이전 포스팅의 마지막 부분에 함수의 리턴값으로 배열을 반환할 수는 없지만 배열의 주소 즉 포인터를 리턴할 수는 있다고 말했었다.
그러면 한 번 실험해보자.
이 함수는 반환값으로 포인터를 return하므로 반환타입은 int*이다.
#include <iostream>
using namespace std;
int* makeArray() {
int arr[5] = { 1, 2, 3, 4, 5 };
return arr; //배열의 주소 반환
}
int main() {
int* myArray = makeArray(); //myArray라는 포인터변수에 배열의 주소를 받음
for (int i = 0; i < 5; i++) {
cout << myArray[i] << endl;
}
return 0;
}
이 코드를 실행하면
위 코드의 실행 결과
1, 2, 3, 4, 5가 아니라 엉뚱한 쓰레기값을 출력하는 것을 볼 수 있다.
이런 결과가 나오는 이유는 함수가 호출될 때 메모리의 스택이 어떻게 동작하는지를 알면 알 수 있다.
#include <iostream>
using namespace std;
int add(int num1, int num2) {
int sum = num1 + num2;
return sum;
}
int main() {
int a = 5;
int b = 2;
int aPlusB = add(a, b);
return 0;
}
이런 코드가 있다고 하자.
이 코드가 실행될 때 스택의 모습은 다음과 같다.
이것과 마찬가지로 위에서 본 이 코드는
#include <iostream>
using namespace std;
int* makeArray() {
int arr[5] = { 1, 2, 3, 4, 5 };
return arr; //배열의 주소 반환
}
int main() {
int* myArray = makeArray(); //myArray라는 포인터변수에 배열의 주소를 받음
for (int i = 0; i < 5; i++) {
cout << myArray[i] << endl;
}
return 0;
}
위 코드가 실행될 때 스택의 모습
이 그림에서 4번째 스택 모습에서 문제가 생기는 것이다.
바로 이 상태이다.
makeArray() 함수가 종료되면서 배열 arr의 시작 주소인 1000번지만 넘겨주고 배열 arr은 스택에서 사라졌는데 1000번지에 가서 1000번지에 있는 쓰레기 값, 1004번지에 있는 쓰레기 값, 1008번지에 있는 쓰레기 값, 1012번지에 있는 쓰레기 값, 1016번지에 있는 쓰레기 값을 출력하고 종료하는 것이다.
바로 이렇게 말이다.
1은 우연히 스택에서 makeArray 함수가 끝나도 그 메모리가 쓰던 곳은 손상되지 않고 남아있어서 아주 운 좋게 1이 출력된 것이다.
일반적으로 프로그램을 실행하면서 필요한 변수들은 대부분 메모리의 스택 영역에 할당된다. 이것을 활성레코드라고 한다. 프로그램이 실행될 때에는 활성레코드 부분이 늘었다 줄었다 하면서 실행되는 것이다. 위에서 본 스택 그림처럼 말이다. 이 문제는 배열이 이러한 스택 영역에 할당되었기 때문에 생기는 문제이다.
이러한 문제를 해결할 수 있는 것이 바로 동적할당이다. 이게 바로 동적 할당이 필요한 이유이다.
스택에 저장된 활성레코드는 그 부분이 실행되고 나면 사라진다. 하지만 메모리에는 스택 영역 말고 힙(heap)이라는 영구 저장소가 있다. 동적 할당을 하면 힙(heap)에 저장이 된다. 힙(heap)에 저장된 것들은 delete를 사용하여 명시적으로 제거하지 않는 이상 프로그램이 종료될 때까지 존재한다.
동적할당은 다음과 같이 new 연산자를 사용하여 한다.
int* p = new int;
new 연산자를 사용하여 동적 배열을 생성하고 싶다면
int* list = new int[SIZE];
이렇게 하면 된다.
동적할당은 포인터 없이는 할 수 없다.
변수에는 동적으로 할당되는 변수가 있고 정적으로 할당되는 변수가 있다. 컴파일러는 컴파일을 할 때 이 프로그램에서 사용할 메모리를 대충 계산한다. 그 다음에 이거를 운영체제에게 알려준다. 예를 들어 컴파일러가 대충 계산했을 때 800바이트가 필요하다 하면 OS는 800바이트 이상을 스택에 여유있게 잡아놓는다. 이게 정적으로 할당하는 것이다.
그렇기 때문에 다음과 같은 코드는 컴파일 에러가 나는 것이다.
#include <iostream>
using namespace std;
int main() {
int size;
cin >> size;
int arr[size];
return 0;
}
사용자에게 size를 입력받아서 그 크기만큼 배열을 잡고 싶은 건데 이러한 코드는 불가능하다. 컴파일 할 때 필요한 메모리를 계산을 해야 하는데 size는 사용자에게 입력받는 것이기 때문에 컴파일 할 때에는 알 수가 없고 실행될 때 값이 결정된다. 따라서 컴파일러는 arr 배열을 메모리에 얼만큼 잡아야 하는지 모르므로 컴파일 에러가 나는 것이다. 따라서 배열의 크기를 정하는 변수는 반드시 const 변수여야 한다.
#include <iostream>
using namespace std;
int main() {
int size = 5;
int arr[size];
return 0;
}
이 코드를 실행해도 컴파일에러가 난다.
배열의 크기를 정하는 저 자리에는 상수 혹은 const 변수(상수 변수)만 들어갈 수 있다.
#include <iostream>
using namespace std;
int main() {
const int size = 5;
int arr[size];
return 0;
}
컴파일에러가 나지 않는다.
이렇게 const를 써줘야만 컴파일 에러가 나지 않는다.
그러면 사용자에게 크기를 입력 받아 그 크기 만큼의 배열을 생성하고 싶다면 어떻게 해야 할까?
동적할당을 사용하면 된다.
#include <iostream>
using namespace std;
int main() {
int size;
cin >> size;
int* arr = new int[size];
return 0;
}
동적할당으로 배열을 생성하면 이렇게 메모리를 얼만큼 잡을지 메모리의 크기를 실행 도중에 정할 수가 있다.
(컴퓨터에서 '동적'이라는 단어가 나오면 실행 도중이라는 뜻이고 '정적'이라는 것은 프로그램 실행 전을 말한다.)
위에서 봤던 코드를 다시 보자.
int* p = new int;
여기에서 포인터변수 p는 정적으로 할당된 변수이다. 포인터변수이므로 컴파일러가 4바이트 만큼을 메모리의 스택 부분에 잡는다. (int라서 4바이트를 잡는 것이 아니다. 이 부분이 헷갈리면 포인터 글을 다시 참고하면 된다.)
하지만 포인터변수 p가 가리키는 int는 동적으로 실행 중에 메모리의 힙(heap) 영역에 잡히게 된다.
일반적인 이진트리 구현방법인 포인터를 이용한 구조체로 트리를 구현했다면 무조건 가장 아래쪽에 있는 노드 D, 노드 E, 노드 G부터 만들어주고 위로 올라가야 한다. 따라서 그냥 이음선의 정보만 주어진다면 트리를 구현하기 위해서 위상정렬까지 해야 하는 상황이 발생한다. 하지만 이렇게 map을 이용해서 이진트리를 구현한다면 순서와 상관없이 이렇게 이음선의 정보만 map에 추가해주면 되기 때문에 트리를 쉽게 구현할 수 있다.
그러면 이렇게 map으로 구현한 이진트리를 전위순회, 중위순회, 후위순회 하는 방법을 알아보자.
void preorder(char node) {//전위순회
cout << node << " "; //현재 노드의 데이터 출력
if (m[node].first != '.') { //왼쪽 자식이 있다면
preorder(m[node].first);
}
if (m[node].second != '.') { //오른쪽 자식이 있다면
preorder(m[node].second);
}
}
void inorder(char node) {//중위순회
if (m[node].first != '.') { //왼쪽 자식이 있다면
inorder(m[node].first);
}
cout << node << " "; //현재 노드의 데이터 출력
if (m[node].second != '.') { //오른쪽 자식이 있다면
inorder(m[node].second);
}
}
void postorder(char node) { //후위순회
if (m[node].first != '.') { //왼쪽 자식이 있다면
postorder(m[node].first);
}
if (m[node].second != '.') { //오른쪽 자식이 있다면
postorder(m[node].second);
}
cout << node << " "; //현재 노드의 데이터 출력
}
이렇게 재귀함수로 쉽게 순회할 수 있다. 만약 자식 노드가 없을 때에 NULL로 저장했다면
왼쪽 자식이 있는지 체크하는 부분을 m[node].first != NULL로
오른쪽 자식이 있는지 체크하는 부분을 m[node].second != NULL로 해주면 된다.
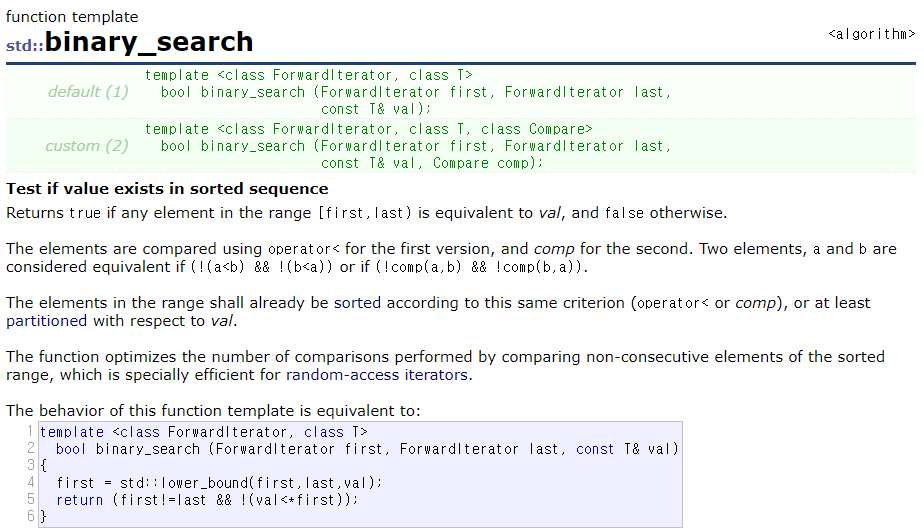
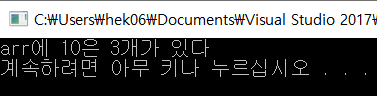
하지만 있는지 없는지 true, false로 반환을 해줄 뿐 어느 인덱스에 있는지는 binary_search 함수로는 알 수 없다.
그래서 사용하는 것이 upper_bound, lower_bound 함수이다.
upper_bound와 lower_bound의 첫 번째, 두 번째 인자는 내가 찾고 싶은 범위를 주소로 지정해주면 된다. 꼭 배열 전체, 벡터 전체일 필요는 없다. 해당 범위를 지정해주고 그 안에 있는지만 찾고 싶으면 그렇게 지정해주면 된다. binary_search 함수의 인자와 똑같다.
세 번째 인자도 binary_search의 세 번째 인자처럼 몇 개 있는지 알고 싶은 그 대상을 적어주면 된다.
lower_bound 함수는 내가 찾고자 하는 그 대상이 저장된 인덱스 중 가장 작은 인덱스를 반환한다.
upper_bound 함수는 내가 찾고자 하는 그 대상이 저장된 인덱스 중 가장 큰 인덱스+1을 반환한다.
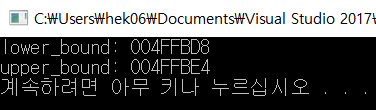
예를 들어 정렬된 arr 배열에 다음과 같이 저장되어 있었다고 하자.
1 3 4 4 7 10 10 10 13 17
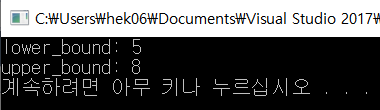
lower_bound(arr, arr + 10, 10)을 한다면 10이 처음 등장하는 인덱스인 인덱스 5의 주소를 반환한다.
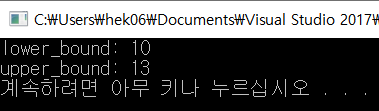
upper_bound(arr, arr + 10, 10)을 한다면 10이 마지막으로 등장하는 인덱스+1인 인덱스 8의 주소을 반환한다.
iterator(메모리 주소)를 반환하기 때문에 몇 번째 인덱스인지 알아보고 싶으면 배열이나 벡터의 시작주소를 빼보면 된다.
일단 lower_bound와 upper_bound 함수의 반환값을 알아보기 위해서 그냥 출력해보면
이렇게 10의 시작인덱스, 10의 마지막 인덱스+1을 출력하는 것을 볼 수 있다. 그 인덱스에 뭐가 들어있는지 알아보고 싶으면 역참조 연산자 *로 데이터에 접근해서 출력해보면 된다. 10의 마지막 인덱스 한 칸 뒤에는 13이 저장되어 있으니 13이 출력될 것을 알 수 있다.
C++에는 조금 더 보기 좋게 출력하게 하기 위해 스트림 조종자(manipulator)가 있다.
스트림 조종자는 <iomanip>과 <iostream> 헤더파일을 포함하면 사용할 수 있다.
사실 boolalpha, showbase, showpoint, dec, hex, oct는 <ios>에 있는 함수들인데 iostream은 ios의 자식 클래스이기 때문에 우리가 C++로 코드를 짤 때 거의 항상 포함하는 <iostream>을 포함해도 사용할 수가 있기 때문에 <iostream>이 있는데 굳이 <ios>를 따로 포함해줄 필요는 없다.
이 표는 manipulator와 그 기능이다.
setprecision(int n)
실수의 정밀도 설정
setw(int n)
출력되는 영역의 폭 설정
setfill(char c)
출력하고 남은 부분을 c로 채움
fixed
실수를 고정된 부동소수점 형식으로
showpoint
실수의 소수점 부분이 없어도 소수점 아래에 0을 표시
left
왼쪽 정렬
right
오른쪽 정렬
boolalpha
bool 값을 1, 0이 아닌 true, false로 출력
showbase
진법기호(16진수의 경우 0x, 8진수의 경우 0)도 출력
dec
정수를 10진수로 출력
hex
정수를 16진수로 출력
oct
정수를 8진수로 출력
다음 코드를 실행하면
#include <iostream>
#include <iomanip>
using namespace std;
int main() {
double a = 3.14159265358979323;
double b = 31.4159265358979323;
double c = 314.159265358979323;
double d = 3141.59265358979323;
double e = 31415.9265358979323;
double f = 314159.265358979323;
double g = 3141592.65358979323;
cout << a << endl;
cout << b << endl;
cout << c << endl;
cout << d << endl;
cout << e << endl;
cout << f << endl;
cout << g << endl;
return 0;
}
이런 결과가 나온다. 즉 실수는 기본적으로 소수점의 위치와는 상관 없이 6자리까지만 표기된다.
그리고 6자리가 넘어가면 3141592.65358979323처럼 3.14159e+06 이렇게 과학적 표기법으로 표기되는데 이게 싫다면 fixed를 이용하면 된다.
#include <iostream>
#include <iomanip>
using namespace std;
int main() {
double a = 3.14159265358979323;
double b = 31.4159265358979323;
double c = 314.159265358979323;
double d = 3141.59265358979323;
double e = 31415.9265358979323;
double f = 314159.265358979323;
double g = 3141592.65358979323;
cout << fixed << a << endl;
cout << b << endl;
cout << c << endl;
cout << d << endl;
cout << e << endl;
cout << f << endl;
cout << g << endl;
return 0;
}
이렇게 fixed만 한 번 써주면
e를 사용한 과학적 표기법이 아니라 우리가 일상에서 쓰는 소수점 표현으로 출력된다. 그리고 fixed를 사용해주니 전체 자리수가 6자리까지가 아니라 소수점 아래 6자리까지 출력된다. fixed는 기본이 소수점 아래 6자리이다.
그런데 실제로 내가 저장한 숫자보다 출력된 숫자가 소수점 아래가 잘려서 정확도가 너무 떨어진다면 setprecision 함수를 사용해서 몇 자리를 표기할지 정해주면 된다.
#include <iostream>
#include <iomanip>
using namespace std;
int main() {
double a = 3.14159265358979323;
double b = 31.4159265358979323;
double c = 314.159265358979323;
double d = 3141.59265358979323;
double e = 31415.9265358979323;
double f = 314159.265358979323;
double g = 3141592.65358979323;
cout << setprecision(18) << a << endl;
cout << b << endl;
cout << c << endl;
cout << d << endl;
cout << e << endl;
cout << f << endl;
cout << g << endl;
return 0;
}
이렇게 setprecision() 함수로 정해주면 18자리가 모두 나타난 것을 볼 수 있다. setprecision() 함수는 한 번만 써주면 setprecision() 함수로 다시 바꾸기 전까지는 계속 유효하다.
하지만 소수점 아래쪽으로 갈수록 정확도가 떨어지는 것을 볼 수 있다.
그럼 setprecision() 함수를 fixed와 같이 써보자.
#include <iostream>
#include <iomanip>
using namespace std;
int main() {
double a = 3.14159265358979323;
double b = 31.4159265358979323;
double c = 314.159265358979323;
double d = 3141.59265358979323;
double e = 31415.9265358979323;
double f = 314159.265358979323;
double g = 3141592.65358979323;
cout << fixed << setprecision(18) << a << endl;
cout << b << endl;
cout << c << endl;
cout << d << endl;
cout << e << endl;
cout << f << endl;
cout << g << endl;
return 0;
}
내가 저장했던 숫자인 314159265358979323까지는 모두 아주 정확하게 출력된 것을 볼 수 있다. 그 아래 자리는 아무 숫자나 출력되었다.
fixed를 사용하고 setprecision() 함수를 사용하면 소수점 아래 몇 번째 자리까지 나타낼 것인지를 정해주는 것이다. 그냥 setprecision() 함수를 사용했을 때에는 소수점과 상관없이 숫자 몇 개를 나타낼지를 정해주는 거였다. 둘의 차이를 기억하자.
그리고 setprecision()을사용할 때에는 원래 숫자의 자릿수보다 더 큰 숫자를 넣으면 저렇게 이상한 숫자가 출력될 수도 있다. 실수는 정수와 달리 저장할 때 정확도가 떨어진다. 모든 정수는 모두 정확한 이진수로 바꿀 수 있지만 실수는 소수점 아래를 정확한 이진수로 표현하기 힘든 경우가 있기 때문이다.
하지만 위의 예처럼 소수점 아래가 매우 많은 숫자 말고 이 정도 숫자는 정확하게 출력한다.
#include <iostream>
#include <iomanip>
using namespace std;
int main() {
double a = 3.14;
double b = 3.1415;
double c = 3.1415926;
cout << setprecision(5) << a << endl;
cout << b << endl;
cout << c << endl;
return 0;
}
그리고 setprecision() 함수를 사용해서 잘린 부분은 그 뒤의 수에서 반올림해서 출력된다.
그런데 만약 모든 수의 소수점 아래 자리가 동일하고 3.14와 같 소수점 아래 숫자가 짧은 것들은 0으로 채우고 싶다면? 그러면 showpoint를 사용하면 된다.
#include <iostream>
#include <iomanip>
using namespace std;
int main() {
double i = 3.0;
double a = 3.14;
double b = 3.1415;
double c = 3.1415926;
cout << i << endl;
cout << showpoint << setprecision(7) << i << endl;
cout << a << endl;
cout << b << endl;
cout << c << endl;
return 0;
}
showpoint를 사용하면 이렇게 3.0과 같은 소수점 아래가 없는 숫자도 내가 정해준 만큼 0을 출력할 수 있다.
그러면 이제 다른 조종자를 배워보자.
#include <iostream>
using namespace std;
int main() {
int arr[10][10];
int num = 1;
for (int i = 0; i < 6; i++) {
for (int j = 0; j < 6; j++) {
arr[i][j] = num;
num++;
}
}
for (int i = 0; i < 6; i++) {
for (int j = 0; j < 6; j++) {
cout << arr[i][j] << " ";
}
cout << endl;
}
return 0;
}
이 코드를 실행하면
이렇게 줄이 안 맞아서 보기 안 좋게 출력된다.
이 때 setw()를 사용하면 줄 맞춰서 예쁘게 출력할 수 있다.
#include <iostream>
#include <iomanip>
using namespace std;
int main() {
int arr[10][10];
int num = 1;
for (int i = 0; i < 6; i++) {
for (int j = 0; j < 6; j++) {
arr[i][j] = num;
num++;
}
}
for (int i = 0; i < 6; i++) {
for (int j = 0; j < 6; j++) {
cout << setw(3) << arr[i][j];
}
cout << endl;
}
return 0;
}
setw()를 이용했더니 이렇게 줄맞춰서 예쁘게 출력되었다.
setw(n)은 n칸을 확보해놓는다는 것이다. 확보해놓고 그 안에서 내가 출력하고 싶은 것을 출력하는 것이다. 확보해놓은 칸보다 내가 출력하고 싶은 것이 더 많은 칸을 차지한다면 자동으로 칸이 증가되기 때문에 잘릴 걱정은 하지 않아도 된다.
setw()를 쓸 때 주의해야 할 것은 setw()를 쓴 직후의 출력에만 유효하다는 것이다.