
안녕하세요
트랜잭션 격리 수준이 무엇인지 알고 계신가요?
트랜잭션 격리는 트랜잭션의 특징 ACID 중 I(Isolation)에 해당합니다.
모든 트랜잭션끼리는 격리되어야 한다는 것입니다.
모든 데이터베이스가 ACID를 모두 완벽하게 만족시키면 좋지만 트랜잭션이 완전히 격리가 되면 그만큼 동시처리 능력도 떨어져 성능이 저하됩니다.
따라서 DBMS는 4가지 트랜잭션 격리 수준을 제공하여 상황에 맞게 선택할 수 있도록 하고 있습니다.
트랜잭션 격리 수준은 4가지가 있는데요, 레벨이 높아질수록 격리성(고립성)은 높아지고 동시 처리 능력은 떨어지게 됩니다.
그럼 이제
- 트랜잭션 격리 수준 4가지
- 읽기 이상 현상 3가지 - dirty read, non-repeatable read, phantom read
- non-repeatable read, phantom read의 차이점
- REPEATABLE READ에서 있던 row가 사라질 수 있나? (대부분의 블로그에 잘못 써있는 사실)
- SERIALIZABLE 격리 수준과 SELECT ... FOR UPDATE문으로 lock을 거는 것과의 차이는?
- 그래서 트랜잭션 격리 수준을 어떻게 지정해줄 수 있는데?
등에 대해 알아보겠습니다.
🥑 READ UNCOMMITTED (레벨 0)
READ UNCOMMITTED는 다른 트랜잭션의 커밋되지 않은 데이터에 접근할 수 있는 격리 수준입니다.
이 격리 수준은 심각한 문제가 있기 때문에 일반적인 데이터베이스에서는 거의 사용되지 않습니다.
어떤 문제가 있을지 예시를 통해 알아봅시다.
김땡땡의 계좌에는 13만원이 있었습니다.
오늘은 김땡땡의 통신비 5만원이 자동이체 되는 날입니다.
1. 통신사의 출금 시스템에서 김땡땡의 통신비를 출금하는 트랜잭션이 시작되었습니다.
2. UPDATE account SET balance=80000 WHERE user_name="김땡땡";
3. 그리고 김땡땡이 온라인 뱅킹 앱으로 통장 잔고를 확인합니다. READ UNCOMMITTED에서는 커밋되지 않은 데이터를 확인할 수 있기 때문에 김땡땡은 계좌에 8만원이 있는 것을 확인합니다.
4. 그 후 자동이체 트랜잭션이 어떠한 이유로 트랜잭션이 롤백되었습니다.
5. 조금 뒤 김땡땡은 다시 잔고를 확인했는데 계좌의 잔고는 13만원입니다.
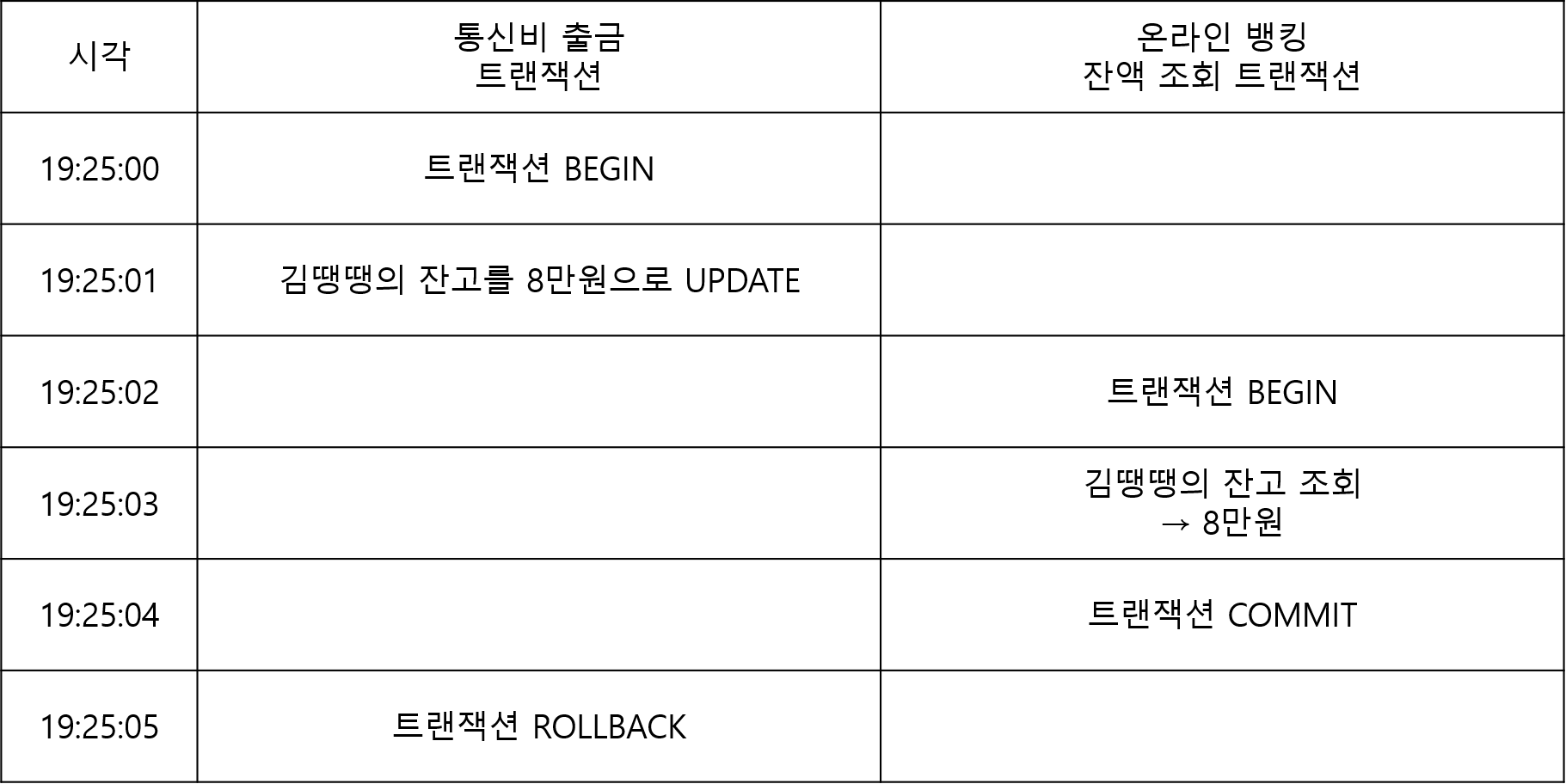
DB에서 김땡땡의 잔고가 8만원이 된 적도 없는데 19시 25분 3초에 온라인 뱅킹 잔액 조회 트랜잭션은 커밋되지 않은 데이터인 8만원을 읽어갔습니다. 실제 잔액은 13만원인데 말이죠.
이것이 바로 dirty read입니다.
읽기만 하면 그나마 다행인데 만약 이렇게 읽은 8만원을 가지고 UPDATE를 했다면 아주 큰 문제가 발생할 것입니다.

김땡땡의 잔고는 15만원이어야 하는데 10만원이 되는 문제가 발생했습니다.
이처럼 READ UNCOMMITTED 격리수준은 큰 문제를 가지고 있어서 거의 사용되지 않습니다.
🥑 READ COMMITED (레벨 1)
READ COMMITTED는 커밋되지 않은 데이터도 읽어왔던 READ UNCOMMITTED와 달리, 커밋된 데이터만 읽어옵니다.
이 격리 수준은 Orable, PostgreSQL 등 많은 RDBMS의 default 격리 수준입니다.
READ UNCOMMITTED 격리 수준에서 발생했던 문제인 dirty read 문제가 발생하지 않습니다.
트랜잭션이 시작되기 전에 COMMIT된 데이터만 조회할 수 있습니다.
하지만 READ COMMITTED도 문제가 있습니다. non-repeatable read 문제가 발생합니다.
non-repeatable read 문제란 무엇일까요?

잔액 조회 트랜잭션에서
SELECT balance FROM account WHERE user_name='김땡땡';이라는 똑같은 쿼리를 두 번 실행했을 때 첫 번째는 130000을, 두 번째는 80000을 받게 됩니다.
이렇게 같은 트랜잭션 내에서 같은 쿼리를 여러 번 실행했을 때 같은 row의 값이 서로 다른 것을 non-repeatable read라고 합니다.
🥑 REPEATABLE READ (레벨 2)
REPEATABLE READ는 한 트랜잭션 내에서 한 번 읽은 데이터는 바뀌지 않는다는 것을 보장하는 격리 수준입니다.
따라서 READ COMMITTED에서 발생했던 non-repeatable read 문제가 발생하지 않습니다.
REPEATABLE READ는 MySQL(MariaDB)의 default 격리 수준입니다.

REPEATABLE READ 격리 수준에서는 여러 번 읽어도 같은 결과가 나오는 것을 보장하는 것은 아니지만 읽은 row들은 변하지 않는 것을 보장합니다.
그럼 어떤 경우에 같은 결과임을 보장하지 못하나요?
새로운 row가 추가될 때입니다.
읽었던 row들은 변하지 않지만 새로운 row가 추가되면 처음 읽었을 때는 없었던 새로운 row도 읽어옵니다.
따라서 처음 읽었을 때는 row 수가 10개였는데 다시 읽었을 때는 row 수가 11이 되는 현상이 발생할 수 있습니다.
이렇게 유령처럼 없던 row가 생기는 것을 phantom read라고 합니다.
그럼 있던 row가 사라지는 경우도 발생하나요? 🤔
아니요!!!!!
없던 row는 새로 생길 수 있지만 있던 row는 사라지지도, 값이 변경되지도 않습니다.
있던 row가 사라지거나 없던 row가 생긴다고 적은 글들이 많은데 이는 잘못된 정보입니다.
대부분의 RDBMS는 REPEATABLE READ 수준에서 phantom read 현상이 발생하지만 MySQL(MariaDB)의 InnoDB 엔진에서는 SNAPSHOT을 이용하기 때문에 phantom read 현상이 발생하지 않는다고 합니다.
🥑 SERIALIZABLE (레벨 3)
SERIALIZABLE 격리 수준은 모든 트랜잭션 작업이 순차적으로 진행되는 격리수준입니다.
따라서 REPEATABLE READ 수준에서 발생했던 Phantom Read 문제가 발생하지 않습니다.
그럼 SELECT ... FOR UPDATE문으로 lock을 거는 것과는 뭐가 다른걸까요?
SELECT ... FOR UPDATE문은 특정 row들에만 lock을 거는 반면 SERIALIZABLE에서는 전체에 lock을 건다는 점입니다.
(물론 RDBMS마다 차이가 있어서 모든 RDBMS가 SERIALIZABLE 수준일 때 전체 lock을 거는 것은 아닙니다.)
그럼 트랜잭션 격리 수준을 변경하려면 어떻게 해야 할까요?
MySQL 기준
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED이렇게 하면 트랜잭션 격리 수준을 변경할 수 있습니다.
만약 현재 세션에서만 격리 수준을 변경하고 싶다면
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED이렇게 해주면 됩니다.
참고
https://dev.mysql.com/doc/refman/8.0/en/innodb-transaction-isolation-levels.html
https://www.sqlshack.com/dirty-reads-and-the-read-uncommitted-isolation-level
https://www.postgresql.kr/docs/13/transaction-iso.html
https://dotnettutorials.net/lesson/non-repeatable-read-concurrency-problem/
https://nesoy.github.io/articles/2019-05/Database-Transaction-isolation
https://www.zghurskyi.com/lost-update/
https://en.wikipedia.org/wiki/Isolation_(database_systems)
https://stackoverflow.com/questions/16957638/serializable-transactions-vs-select-for-update
'데이터베이스' 카테고리의 다른 글
| [DB] Optimistic Locking vs Pessimistic Locking (0) | 2023.03.13 |
|---|


