public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int n = in.nextInt();
int[] arr = new int[1000001];
arr[1] = 1;
arr[2] = 2;
for (int i = 3; i < 1000001; i++) {
arr[i] = arr[i - 2] + arr[i - 1];
}
System.out.print(arr[n] % 15746);
}
}
이렇게 했는데 자꾸 틀렸다는거다
아무리 봐도 맞는데 뭐가 틀리다는건지 몰라서 너무 답답했지만 그래도 스스로 풀어내겠다는 오기로 풀었다
그런데도 계속 틀리다는거다
그래서 결국 구글링을 해봤더니 다들 저장할 때부터 15746으로 나눈 나머지를 저장하더라
설마 하고 똑같은 코드에 % 15746 이것만 붙여서 했더니 맞았다고 떴다.
public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int n = in.nextInt();
int[] arr = new int[1000001];
arr[1] = 1;
arr[2] = 2;
for (int i = 3; i < 1000001; i++) {
arr[i] = arr[i - 2] % 15746 + arr[i - 1] % 15746;
}
System.out.print(arr[n] % 15746);
}
}
너무 허무했다.
길이가 N인 2진 수열의 개수를 15746으로 나눈 나머지를 출력하라고 해서 출력할 때만 15746으로 나눈 나머지를 출력했는데 왜 저장할 때도 15746으로 나눈 나머지를 저장해야 하는지 모르겠었다.
그런데 생각해보니 피보나치 수열은 기하급수적으로 증가하기 때문에 오버플로우가 난다.
int로 하면 47번째부터, long으로 해도 93번째부터 오버플로우가 난다.
따라서 애초에 저장할 때 나머지를 저장해주어 오버플로우를 방지한 것이다.
몇 분만에 푼 문제를 괜히 몇 시간 시간낭비했다는 생각이 들었었지만 덕분에 깨달은 게 있으니 다행인 것 같다. 다음부턴 이런 실수 하지 말아야지.
public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int n = in.nextInt();
ArrayList list = new ArrayList<>();
for (int i = 0; i < 3000000; i++) {
if(String.valueOf(i).contains("666"))
list.add(i);
}
System.out.println(list.get(n - 1));
}
}
처음에는
public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int n = in.nextInt();
String s = "666";
HashSet set = new HashSet<>();
for (int i = 0; i < 10000; i++) {
if(String.valueOf(i).length() == 1) {
set.add(Integer.parseInt(s + i));
set.add(Integer.parseInt(i + s));
}
else if (String.valueOf(i).length() == 2) {
set.add(Integer.parseInt(s + i));
set.add(Integer.parseInt(i + s));
set.add(Integer.parseInt(String.valueOf(i).charAt(0) + s + String.valueOf(i).charAt(1)));
}
else if (String.valueOf(i).length() == 3) {
set.add(Integer.parseInt(s + i));
set.add(Integer.parseInt(i + s));
set.add(Integer.parseInt(String.valueOf(i).charAt(0) + s + String.valueOf(i).substring(1, 3)));
set.add(Integer.parseInt(String.valueOf(i).substring(0, 2) + s + String.valueOf(i).charAt(2)));
}
else {
set.add(Integer.parseInt(s + i));
set.add(Integer.parseInt(i + s));
set.add(Integer.parseInt(String.valueOf(i).charAt(0) + s + String.valueOf(i).substring(1, 4)));
set.add(Integer.parseInt(String.valueOf(i).substring(0, 2) + s + String.valueOf(i).substring(2, 4)));
set.add(Integer.parseInt(String.valueOf(i).substring(0, 3) + s + String.valueOf(i).charAt(3)));
}
}
ArrayList list = new ArrayList<>(set);
list.sort((a, b) -> a - b);
System.out.println(list.get(n - 1));
}
}
이렇게 했는데 자꾸 틀렸다고 나오는거다.
그래서 포기하고 구글링을 해봤더니 자바의 String 클래스에 contains()라는 메소드가 있었다.
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int n = in.nextInt();
int m = in.nextInt();
char[][] arr = new char[n][m];
String[] starr = new String[n];
for (int i = 0; i < n; i++) {
starr[i] = in.next();
}
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
arr[i][j] = starr[i].charAt(j);
}
}
int min = 2500;
//첫번째 칸이 흰색인 경우 case1
//첫번째 칸이 검은색인 경우 case2
for (int i = 0; i <= n - 8; i++) {
for (int j = 0; j <= m - 8; j++) {
int case1 = 0;
int case2 = 0;
for (int k = 0; k < 8; k++) {
for (int l = 0; l < 8; l++) {
if (arr[i + k][j + l] == 'W') {
if (k % 2 == 0 && l % 2 == 0) {
case2++;
}
else if (k % 2 == 0 && l % 2 == 1) {
case1++;
}
else if (k % 2 == 1 && l % 2 == 0) {
case1++;
}
else {
case2++;
}
}
else {
if (k % 2 == 0 && l % 2 == 0) {
case1++;
}
else if (k % 2 == 0 && l % 2 == 1) {
case2++;
}
else if (k % 2 == 1 && l % 2 == 0) {
case2++;
}
else {
case1++;
}
}
}
}
if (case1 < min) {
min = case1;
}
if (case2 < min) {
min = case2;
}
}
}
System.out.println(min);
}
}
C/C++에는 함수포인터라는 개념이 있어 함수를 다른 함수로 전달하고 싶을 때에는 함수 포인터를 사용하면 된다.
그런데 자바는 C/C++보다 더 객체지향적인 언어이기 때문에 메소드(C/C++로 따지면 함수)는 무조건 클래스의 내부에 있어야 한다.
따라서 메소드를 전달하고 싶을 때도 (행위를 전달하고 싶을 때도) 메소드만 전달할 수는 없고 클래스를 만들어 그 안에 메소드를 정의하고 그 클래스의 객체를생성해서넘겨줘야 한다.
람다식은 객체를 생성하는 방법 중 하나이다. 람다식을 사용하면 객체가 생성된다.
자바에는 인터페이스라는 개념이 있다. 인터페이스는 추상클래스의 극단적인 형태라고 보면 된다.
인터페이스는 구현되어 있는 메소드가 없고 모두 추상메소드로만 이루어져 있다. (JDK 8부터 default 메소드와 static 메소드, JDK 9부터 private 메소드는 예외적으로 구현메소드가 가능하다)
인터페이스를 구현하는 클래스는 그 추상메소드를 반드시 구현해야 한다.
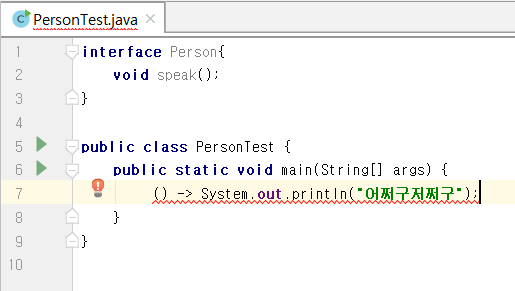
아래의 코드를 보면 speak()라는 아직 구현되지 않은 추상메소드가 있기 때문에 Person 객체를 생성할 수 없다고 컴파일 에러가 난다.
따라서 Person 타입의 객체를 생성하기 위해서는 speak 메소드를 구현해줄 필요가 있다.
그 방법으로 그 인터페이스를 구현하는 MyPerson이라는 클래스를 새로 만들고 그 클래스를 이용해 새로운 객체를 만드는 방법이 있다.
아래의 코드가 그 방법을 사용한 것이다.
interface Person{
void speak();
}
public class PersonTest {
public static void main(String[] args) {
Person p = new MyPerson();
p.speak();
}
}
class MyPerson implements Person {
public void speak(){
System.out.println("어쩌구저쩌구");
}
}
Person 인터페이스를 구현하는 MyPerson이라는 클래스를 만들어서 speak() 메소드를 구현해주었다.
그러나 이것은 너무 비효율적이고 번거롭다. 딱 한 번만 쓰고 말 객체인데도 그 객체를 만들기 위해서 Person 인터페이스를 구현하는 MyPerson이라는 클래스를 새로 만들었다. 이러한 비효율적인 문제는 무명객체를 만들어 해결할 수 있다.
new 인터페이스나 추상클래스(){정의되지 않은 메소드};
예를 들어 new Person(){메소드};
이렇게 그 중괄호 안에 구현되지 않은 메소드를 정의해주는 것이 무명객체를 생성하는 방법이다.
interface Person{
void speak();
}
public class PersonTest {
public static void main(String[] args) {
Person p = new Person() {
@Override
public void speak() {
System.out.println("어쩌구저쩌구");
}
};
p.speak();
}
}
이렇게 말이다.
무명객체 안에서 메소드를 오버라이딩하기 위해서는 메소드의 시그니쳐(매개변수 개수, 매개변수 타입, 메소드 이름)와 반환타입이 인터페이스에 정의된 메소드 헤더와 일치해야 한다. 참고로 인터페이스의 추상메소드는 앞에 public이라고 써있지 않아도 무조건 public이다. 따라서 public void speak(){} 하고 중괄호 사이에 speak 메소드가 수행할 코드를 적어주는 것이다.
하지만 무명객체를 선언하는 것도 번거롭고 코드가 꽤 길다. 단 한 번만 사용할 객체라 클래스의 이름은 선언하지 않았지만 클래스를 정의하는 것과 똑같이 메소드의 반환타입, 매개변수, 메소드 이름도 적어야 하고, 메소드 내용을 직접 정의해줘야 한다. 정말 꼭 필요한 것은 메소드 내부의 코드인데 말이다.
그래서 나온 것이 람다식이다. 람다식을 쓴다는 것은 인터페이스를 구현한 객체를 만드는 것이다. 예를 들어 Person이라는 클래스가 있을 때
new Person(); 한 것과 똑같이 객체를 하나 선언하는 것이다. 다만 그 객체는 이름이 없는 무명객체일 뿐이고 객체를 생성할 때 new를 사용하지 않았을 뿐이다.
람다식을 사용할 수 있는 조건은 제한적이다.
일단 람다식은 구현하는 인터페이스에 추상메소드가 딱 1개 있을 때에만 가능하다.
추상 클래스에 추상메소드가 딱 1개 있을 때도 안 된다. 꼭 인터페이스에 추상메소드가 1개 있어야 한다.
추상메소드가 1개만 있는 인터페이스를 함수형 인터페이스라고 한다.
람다식을 사용한다는 것은 구현되지 않은 메소드를 정의해주는 것이다. 그리고 그 결과로 객체가 생성된다.
어느 한 클래스의 인스턴스 메소드가 하나라도 구현되지 않았으면 객체를 생성할 수가 없다.
즉, 인터페이스는 객체 생성이 불가능하다.
그래서 그 메소드 내부를 구현해줘야 객체를 생성할 수 있는데 람다식은 편리성을 위해 어느 메소드를 구현하는지 메소드 이름을 쓰지 않고 그 메소드 내부 코드만 적어주는 방법이다.
그런데 아직 구현되지 않은 메소드가 여러 개라면 이 코드가 어느 메소드를 구현하는 코드인지 알 수가 없다.
따라서 인터페이스에 추상메소드가 딱 1개 있을 때에만 람다식을 쓸 수 있다. 만약 구현되지 않은 메소드가 2개 이상이라면 위의 두 가지 방식(익명 객체 생성, 구현 클래스 만들어서 객체 생성) 중 하나를 사용해야 한다.
다음과 같이 Person이라는 인터페이스가 있고 그 안에 speak()라는 추상메소드가 있다. Person 객체를 생성해서 그 객체가 speak라는 행위를 하도록 하고 싶을 때
interface Person{
void speak();
}
public class PersonTest {
public static void main(String[] args) {
Person p1 = () -> System.out.println("어쩌구저쩌구");
Person p2 = () -> System.out.println("배고프다");
p1.speak();
p2.speak();
}
}
이렇게 람다식을 이용해서 간단히 Person 객체를 생성할 수 있다. 내가 원하는 코드로 speak() 메소드의 내부를 구현해주는 것이다.
따라서 람다식을 이용해서 speak 메소드의 내부를 구현해주는 것이다.
람다식 규칙은
(매개변수)->{메소드 내부 코드;}
인데 speak() 메소드의 매개변수는 없으므로 () 이렇게 빈 괄호를 쳐주는 것이다. 그리고 p1은 speak 메소드를 실행했을 때에 "어쩌구저쩌구"을 출력하고 싶고 p2는 "배고프다"를 출력하고 싶으므로 그렇게 speak 메소드를 정의한 것이다.
그렇게 speak 메소드를 정의한 후에 객체.speak()로 speak 메소드를 실행하는 것이다.
실행한 결과이다.
이렇게 우리가 speak 메소드를 정의해준대로 실행하는 것을 알 수 있다.
람다식에서 메소드 내부 코드를 감싸는 중괄호는 실행문이 한 문장일 때에는 생략 가능하다. 그리고 한 문장일 경우 세미콜론도 생략 가능하다.
위의 코드에서 speak 메소드의 내부 코드는 한 줄이므로 중괄호와 세미콜론을 생략했다. 끝에 있는 세미콜론은 System.out.println("어쩌구저쩌구") 문장의 종결을 의미하는 세미콜론이 아니라 Person p1 = new Person() 뒤에 찍는 그 세미콜론과 같다.
또한 메소드의 매개변수가 1개라면 인자를 감싸는 소괄호도 생략 가능하다.
interface ChangeNumber {
int increase(int n);
}
public class LambdaTest {
public static void main(String[] args) {
ChangeNumber c = a -> a + 10;
printChangeNumber(c, 7);
printChangeNumber(c, 9);
printChangeNumber(x -> x + 5, 10); //5를 증가하도록 하는 ChangeNumber 객체를 넘겨줌
}
static void printChangeNumber(ChangeNumber changeNumber, int num) {
System.out.println(changeNumber.increase(num));
}
}
printChangeNumber() 메소드를 총 3번 호출했고 첫 번째, 두 번째는 10씩 증가시켰고 세 번째 수는 5 증가시켰다.
ChangeNumber 인터페이스의 increase 메소드의 매개변수가 n 한 개이기 때문에 (a) -> a + 10 하지 않고 a -> a + 10 이렇게 괄호를 생략할 수 있다. 그리고 실행문이 한 개이기 때문에 a -> {a + b;} 이렇게 중괄호를 생략할 수 있다.
처음에는 ChangeNumber c = a -> a + 10; 이렇게 인터페이스 객체를 c에 저장해주었고
마지막에는 x -> x + 5라는 ChangeNumber 객체를 바로 printChangeNumber() 메소드의 인자로 넘겨주었다.
람다식에서 쓰는 매개변수의 이름은 상관이 없다. a를 써도 되고 x를 써도 되고 number -> number + 10 이렇게 해도 된다.
만약 람다식을 쓰지 않았더라면
interface ChangeNumber {
int increase(int n);
}
public class LambdaTest {
public static void main(String[] args) {
ChangeNumber c = new ChangeNumber() {
@Override
public int increase(int n) {
return n + 10;
}
};
printChangeNumber(c, 7);
printChangeNumber(c, 9);
printChangeNumber(new ChangeNumber() {
@Override
public int increase(int n) {
return n + 5;
}
}, 10); //10을 5 만큼 증가하도록 하는 ChangeNumber 객체를 넘겨줌
}
static void printChangeNumber(ChangeNumber changeNumber, int num) {
System.out.println(changeNumber.increase(num));
}
}
코드가 이렇게 길어졌을 것이다. 이 코드는 람다식을 쓴 위의 코드와 정확히 똑같은 코드이다. 그런데 훨씬 길고 복잡하다. 람다식을 쓰면 이렇게 불필요한 코드를 줄일 수 있다.
그러면 우리가 () -> System.out.println("배고프다")를 쳤을 때 그게 Person 객체를 생성하고 싶은 것인지 어떻게 아는 걸까? 매개변수가 없는 추상메소드를 가지는 또 다른 인터페이스가 있으면 저게 어느 인터페이스를 구현하는 객체인지 어떻게 아는 걸까?
우리가 a -> a + 10 했을 때 그게 ChangeNumber 객체를 생성하고 싶은건지 어떻게 아는 것일까?
() -> System.out.println("배고프다"), a -> a + 10 앞에 각각 Person p, ChangeNumber c 이렇게 타입을 선언했기 때문이다. 따라서 Person 타입의 p라는 변수를 선언함으로 이 람다식이 Person 타입의 객체를 생성한다는 것을 추론할 수 있고 ChangeNumber 타입의 c라는 변수를 선언함으로써 ChangeNumber 타입의 객체를 생성한다는 것을 추론할 수 있다.
만약에 Person p = ()->System.out.println("어쩌구저쩌구");에서 앞에 Person p =을 붙이지 않는다면 다음과 같이 컴파일 에러가 발생한다. 타입을 전혀 추론할 수 없기 때문이다.
Person p = ()-&gt;System.out.println("어쩌구저쩌구");로 하지 않았을 때
그러면 변수 선언이 아니라 람다식을 메소드의 인자로 쓸 경우에는 타입을 적어주지 않았는데 어떻게 타입을 추론하는 것일까?
메소드는 이미 정의되어 있고 메소드에는 매개변수의 타입까지 정의되어 있으므로 인자로 넣었을 때 그 메소드의 매개변수 타입으로 추론할 수 있다.
personSpeak 메소드를 정의할 때 personSpeak 메소드의 매개변수는 한 개이고 그 타입은 Person 타입이라는 것을 8~10줄에 정의해놓았다. 따라서 메인메소드에서 personSpeak 메소드를 호출해서 사용할 때에 인자로 람다식을 넣어줘도 그 람다식이 Person 타입의 객체라는 것을 추론할 수 있다.
다시 한 번 말하지만 람다식을 사용한다는 것은 객체를 생성하는 것이다. 무명객체를 생성해서 personSpeak 메소드의 인자로 넘기는 것이다. 그러니까 6번째 줄의 ()->System.out.println("안녕)"은 Person 타입의 객체를 생성한 것이다.
사실 이렇게 우리가 정의한 인터페이스 객체를 만드는 경우보다는 Java에 원래 있는 인터페이스를 우리가 구현하는 경우가 대부분이다. 정렬을 할 때에 비교기준을 정의해줄 때 사용하는 Comparator, 스트림에서의 인자인 Predicate, Consumer, Supplier, Operator 등은 모두 추상메소드가 1개인 함수형 인터페이스이다. 따라서 람다식을 매우 유용하게 이용할 수 있다. 이는 다음 포스팅에서 자세히 설명하겠다.
자바에 문자열을 담을 수 있는 클래스로 String, StringBuilder, StringBuffer라는 클래스들이 있는데 약간씩 차이가 있다.
일단 가장 큰 차이점은 String은 문자열을 변경할 수 없지만 StringBuilder, StringBuffer는 문자열을 변경 가능한 variable 클래스이다.
String 클래스는 final 클래스이다.
클래스가 final이라는 말은 String 클래스를 상속받아 파생클래스를 만들 수가 없다는 것이다.
또한 String 클래스는 Comparable 인터페이스를 구현(implement)한 클래스이다. Comparable 인터페이스의 구현 클래스는 compareTo라는 메소드를 반드시 구현해야 하므로 String 클래스 안에는 compareTo 메소드가 있다.
두 객체를 비교하기 위해서는 compareTo 메소드가 있어야 한다.
예를 들어
class Person {
}
public class PersonTest {
public static void main(String args[]){
Person p1 = new Person();
Person p2 = new Person();
}
}
이렇게 선언을 하고 p1과 p2를 비교하는 것은 불가능하다. 비교 기준이 없기 때문이다.
만약에 p1 객체와 p2 객체를 비교하고 싶다면
class Person implements Comparable {
int age;
String name;
public Person(int age, String name) {
this.age = age;
this.name = name;
}
@Override
public int compareTo(Person p) {
return age - p.age;
}
@Override
public String toString() {
return name + "(" + age + ")";
}
}
public class PersonTest {
public static void main(String[] args) {
Person p1 = new Person(15, "철수");
Person p2 = new Person(12, "영희");
Person p3 = new Person(17, "순이");
ArrayList people = new ArrayList<>();
people.add(p1);
people.add(p2);
people.add(p3);
Collections.sort(people);
System.out.println(people);
}
}
이렇게 Comparable 인터페이스를 상속받아 compareTo 메소드를 통해 비교기준을 제시해야 한다.
이 코드에서는 나이를 비교 기준으로 제시하였다.
이 코드를 실행한 결과는 다음과 같다.
compareTo 메소드를 나이 순으로 정의하고 정렬한 결과
String 클래스는 compareTo 메소드가 구현되어 있으므로 비교 기준이 설정되어 있다. 그 비교 기준은 알파벳 순서 오름차순이고 소문자보다 대문자가 우선이다. 예를 들어 C, c, d, D가 있고 이것을 정렬한다면 C, D, c, d가 된다. String 클래스는 final 클래스이기 때문에 이러한 비교기준을 변경할 수 없다.
String 객체는 정적인 문자열이다. 즉, 변경 불가능한 고정 문자열이라는 뜻이다.
'String 객체도 + 연산자 써서 문자열 변경 가능하던데?' 할 수 있다. 하지만
String s = "a"; //①
이렇게 해 놓고
s = s + "b"; //②
하면 ①에서의 객체 s와 ②에서의 객체 s는 전혀 다른 객체이다. ①에서의 그 객체에 "b"를 붙여서 "ab"가 되는 것이 아니라 ①에서의 "a" 문자열 객체는 가비지가 되어버리고 "ab"라는 새로운 객체를 만들어 s라는 변수가 새로 만들어진 객체 "ab"를 가리키도록 하는 것이다. 그러나 StringBuffer와 StringBuilder는 그렇지 않다.
StringBuilder와 StringBuffer는
StringBuffer sb = "a"; //또는 StringBuilder sb = "a" //③
이렇게 해 놓고
sb.append("b"); //④
해도 ③에서의 객체와 ④에서의 객체는 같은 객체이고 그 객체에 "b"라는 문자열을 append 한 것 뿐이다. 객체를 새로 만드는 과정이 이루어지지 않는다. (참고로 String은 고정문자열이니 당연히 append 메소드가 없고 StringBuilder와 StringBuffer는 가변 문자열이므로 append 메소드가 있다. 대신 + 연산자로 문자열을 붙이는 것은 불가능하다.)
따라서 문자열이 자주 바뀌어야 한다면 String보다는 StringBuilder나 StringBuffer를 쓰는게 시간적으로나 메모리 공간적으로나 훨씬 효율적이다.
시간적으로 StringBuilder/StringBuffer가 더 효율적이라는 사실은 실제로 이 코드를 돌려보면 알 수 있다.
public class StringTest {
public static void main(String[] args) {
String s = "a";
long before = System.nanoTime();
appendString(s);
long after = System.nanoTime();
System.out.println("String을 썼을 때에 걸린 밀리초: " + (after - before));
StringBuilder sb = new StringBuilder("a");
before = System.nanoTime();
appendStringBuilder(sb);
after = System.nanoTime();
System.out.println("StringBuffer를 썼을 때에 걸린 밀리초: " + (after - before));
}
static void appendString(String s){
for(int i = 0; i < 1000; i++){
s = s + "a";
}
}
static void appendStringBuilder(StringBuilder s){
for(int i = 0; i < 1000; i++){
s.append("a");
}
}
}
위의 코드를 돌린 결과는 아래와 같다.
String을 사용했을 때와 StringBuilder를 사용했을 때 걸리는 시간
String을 사용했을 때, StringBuilder를 사용했을 때보다 약 500배 정도 더 걸리는 것을 볼 수 있다.
다만 StringBuilder와 StringBuffer의 차이점은 StringBuffer는 동기화 기능이 있어서 멀티 스레딩을 해야 할 때 사용한다. 따라서 멀티 스레딩을 쓰지 않는다면 StringBuilder를 사용하는 것이 일반적이다.
플랫폼 독립적이라는 것의 의미는 한 번 짠 그 코드는 이 컴퓨터에서도 돌아가고 운영체제와 CPU와 전혀 상관없이 다른 컴퓨터에서도 똑같이 잘 돌아간다는 것을 의미한다. CPU와 운영체제가 서로 다른 컴퓨터에서도 말이다.
따라서 플랫폼 종속적인 프로그래밍 언어들은 운영체제에 따라, 하드웨어(CPU)에 따라서는 그 코드가 돌아가지 않을 수도 있다는 불편함이 있다. 이것을 이식성(portability)이 낮다고 말한다. (이식성이 높은 프로그램은 이 컴퓨터에서도, 저 컴퓨터에서도 잘 돌아가는 것을 말한다.)
①하드웨어에 따라 왜 다르냐?
하드웨어 아키텍처마다 사용하는 기계어 종류가 다름. ex) 인텔 CPU와 AMD CPU는 사용하는 기계어가 다름.
그런데 실행코드는 기계어로 되어 있음. 기계(CPU)에게 일을 시켜야 하는데 CPU는 기계어 밖에 못 알아들으니까.
따라서 당연히 다를 수밖에 없음
②운영체제에 따라 왜 다르냐?
②-⑴운영체제가 사용하는 API 형식이 다름.
API(Application Programming Interface)란? 응용프로그램이 운영체제의 기능을 사용하고 싶을 때 (운영체제에게 일을 시키고 싶을 때) 프로그래밍 언어를 통해서 운영체제에게 특정 기능을 요청할 수 있는 함수라고 할 수 있음.
응용프로그램도 운영체제가 제공하는 API 함수를 이용해서 간접적으로 하드웨어에 접근할 수 있는거임. 운영체제만이 하드웨어를 직접 제어하기 때문.
따라서 컴퓨터 하나는 운영체제가 리눅스이고 또 다른 하나는 윈도우즈라면 당연히 운영체제가 제공하는 API 형식이 다르므로 프로그램에서 사용하는 함수 이름이 달라지고 (운영체제가 달라도 API 함수 이름이 같으면 상관없겠지만.) 코드도 달라질 수밖에 없다.
②-⑵운영체제마다 메모리를 관리하는 기법이 다름.
프로그램을 실행하려면 운영체제는 메모리(메인메모리, RAM)를 사용하게 되는데 운영체제마다 메모리를 관리하는 기법이 다르다.
이러한 이유들 때문에 대부분의 프로그래밍 언어들은 플랫폼 종속적인 것이다. 그러나 자바는 그렇지 않다.
자바 프로그램을 자바 컴파일러가 컴파일 하면 바이트코드가 만들어지는데 이 바이트코드는 자바 플랫폼(JVM)에서 돌아간다.
여기서 헷갈리지 말아야 할 것은 '자바 플랫폼'은 플랫폼 '종속적'이다. 따라서 실제로 오라클 홈페이지에서 JDK를 다운받을 때에 mac OS용, Windows용, Linux용이 따로 있다. 하지만 이렇게 플랫폼 종속적인 JVM만 설치되어 있으면 자바 프로그램은 플랫폼 독립적이다. (JVM도 사실상 운영체제라고 볼 수 있다. 메모리를 관리하는 능력이 있기 때문) Windows용이든 mac OS용이든 Linux용이든 자바 플랫폼 위에서는 똑같은 코드가 멀쩡히 다 돌아갈 수 있는 것이다.
-C/C++ vs Java
①실행 환경
C/C++ 프로그램을 작성하여 컴파일러를 통해서 목적코드가 만들어지면 목적코드 안에 printf나 cout 같은 함수가 있을 수 있다. 그런데 이러한 함수는 내가 만든 함수가 아니다. 따라서 이 함수 호출 부분을 라이브러리 안에 있는 함수와 연결시켜줘야 하는데 그것을 링크(link)라고 한다. C/C++의 경우 프로그램 실행 전에 링크를 하므로 정적인 링킹(static linkng)이다. 그 후 운영체제 위에서 프로그램이 돌아갈 때 printf나 cout 같은 함수들이 링크되어있기 때문에 그 함수가 있는 라이브러리가 프로그램 안에 포함되어 있는 것이다. 따라서 자연히 프로그램의 크기도 커지게 된다.
그러나 자바는 다르다. 자바는 정적인 링킹이 아니라 동적인 로딩을 한다.
자바는 자바 컴파일러가 바이트코드로 만들면(컴파일 방식) 링크 과정 없이 그 바이트 코드를 JVM에서 바로 실행한다. (인터프리터 방식으로) 그 프로그램을 실행하는 동안에 printf 메소드가 필요하다면 JVM의 클래스로더가 그 때 링크를 시켜주는 것이다. 필요할 때에 가져오고 반납하고 하는 것이다. 실행 도중에. 그렇다고 자바 프로그램의 크기가 작은 것은 아니다. 방식이 달라서 크기 비교는 어렵다.
②메모리 관리 기법
C/C++에서는 응용프로그램에서 메모리가 필요하면 함수를 사용해 메모리를 직접 할당할 수 있다. C에서의 malloc 함수, C++에서의 new 함수가 그것이다. 운영체제의 도움을 받아서 프로그램에서 필요한 만큼의 메모리를 할당받는 것이다.
참고로 운영체제의 가장 큰 역할은 자원 관리자(resource manager)이다. CPU, 메모리 등의 자원을 관리하는 것이다.
따라서 C 프로그램에서 이만큼의 메모리가 필요하니까 메모리를 할당해달라고 운영체제에게 요청을 하면 운영체제가 메모리에 여유가 있는지 확인하고 여유가 있다면 그만큼의 메모리를 할당해준다. 그러면 그 할당 받은 메모리를 사용해서 프로그램이 실행되는 것이다. 또한 그렇게 할당받은 메모리를 다 사용했다면 C에서는 free 함수, C++에서는 delete 함수를 호출하여 운영체제에게 자원을 반납해야 한다.
그러나 자바는 그렇지 않다. 자바 프로그램은 JVM 위에서 돌아가는데 JVM은 운영체제로부터 메모리를 미리 할당받아 놓고 자기가 관리를 한다. 따라서 자바에서 new 함수를 호출하면 운영체제의 도움이 아니라 JVM의 도움으로 메모리를 할당받아서 사용하는 것이다. 그런데 여기서 또 하나 C/C++과 다른 점이 있다.
자바에는 new 함수는 있지만 free(또는 delete) 함수는 없다는 것이다. 자바에는 가비지 컬렉터(Garbage Collector)가 있기 때문에 알아서 다 쓰고 난 메모리 자원을 수거한다. 따라서 자바에서는 메모리 누수 걱정을 하지 않아도 된다는 장점이 있다. 하지만 가비지 컬렉터가 가비지를 모으려고 돌아다니면 그 때 프로그램의 속도가 느려질 수 있다는 단점도 있다. 그래서 JDK 11부터는 속도를 개선시키기 위해서 ZGC(A Scalable Low-Latency Garbage Collector)라는 새로운 가비지 컬렉터를 사용한다. (약자가 왜 ZGC냐면 처음에는 Zero Latency Garbage Collector로 하려고 했으나 현실적으로 Zero Latency는 불가능하기 때문에 약자는 ZGC이지만 풀이는 다르다고 한다.)