그리고 JVM이 실행을 하면서 해당 바이트코드를 한 줄씩 읽으면서 기계어로 해석(interpret)합니다.
JIT 컴파일러는 자주 호출되는 메소드나 자주 실행되는 코드 블럭을 미리 기계어로 번역하여 캐싱을 해둡니다.
그리고 이 자주 실행되는 부분을 'HotSpot'이라고 합니다.
그럼 JIT 컴파일은 언제 수행될까요?
컴파일 타임에 수행될까요? 런타임에 수행될까요?
런타임에 실행됩니다.
보통 '컴파일'이라고 하면 말 그대로 컴파일 타임에 수행이 됩니다.
하지만 JIT 컴파일러는 런타임에 수행됩니다.
왜 런타임에 수행하는 것일까요?
그 전에 컴파일 방식과인터프리터 방식의 장단점에 대해서 살펴보겠습니다.
컴파일 방식의 단점
컴파일 방식의 단점은 시작 시간이 오래 걸린다는 것입니다. 프로그램의 성능은 좋아지겠지만 시작 시간이 너무 오래 걸립니다.
실행을 하려면 컴파일(기계어로의 컴파일) 과정을 거쳐야 합니다.개발자가 코드를 한 줄만 수정해도 다시 컴파일을 해야 하기 때문에 프로그램이 시작 시간이 느리다는 단점이 있습니다.
('개발자가 코드를 한 줄만 수정해도 자바 컴파일러의 컴파일(javac)은 해야 하는데 그럼 이거는?'이라고 생각하실 수 있습니다. 하지만 Java 코드를 바이트코드로 컴파일하는 것은 아주 빠르게 수행됩니다. 또한 자바 컴파일러는 수정된 부분의 코드만 다시 컴파일을 하고 기존 코드는 재사용하기 때문에 일반적인 컴파일(기계어로의 컴파일)보다 훨씬 빠릅니다.)
컴파일 방식의 장점
하지만 컴파일을 한 번만 하고 실행을 많이 한다면 컴파일 방식이 유리할 것입니다.
예를 들어, 어떤 프로그램을 CD에 담아서 대량 생산을 한다면 컴파일 방식이 유리할 것입니다.
한 번만 컴파일 해놓으면 그 실행파일을 CD에 담기만 하면 되기 때문입니다. 해당 프로그램은 실행 시간 중에 기계어로 번역하는 작업을 하지 않고 이미 번역되어 있는 기계어를 바로 실행하기 때문에,컴파일을 할 때는 오래 걸려서 답답할 수도 있겠지만사용자는 아주 빠른 성능의 프로그램을 사용할 수 있을 것입니다.
즉, 컴파일 방식의 장점은 실행 속도가 빠르다는 것입니다.
이러한 장점 때문에 대규모 계산이 필요한 고성능 컴퓨팅 분야에서는 여전히 Fortran과 C언어를 사용하는 것입니다.
(참고로 Fortran은 최초의 프로그래밍 언어입니다😉)
그렇다면 인터프리터 방식은 어떨까요?
인터프리터 방식은 실행하기 전에 전체 코드를 기계어로 번역하는 작업(컴파일)을 하지 않아도 되므로 시작 시간은 컴파일 방식에 비해서 빠를 것입니다. 하지만 실행 중에 코드를 기계어로 번역하는 작업을 해야 하기 때문에 실행 속도는 컴파일 방식보다 느릴 것입니다.
예를 들어서 설명하겠습니다.
예를 들어 A라는 메소드가 있습니다.
컴파일 방식일 때, A 메소드는 컴파일하는데 1초가 걸리고 실행하는데 1초가 걸린다고 합시다.
인터프리트 방식일 때, A 메소드는 인터프리터가 한 줄씩 기계어로 해석했을 때 총 해석시간이 1초이며 한 줄씩 실행할 때 총 실행 시간이 1초가 걸린다고 합시다.
(사실 이렇지 않습니다. 컴파일은 코드 전체를 번역하면서 최적화 작업을 진행하기 때문에 컴파일러가 기계어로 번역을 하는 시간은 인터프리터가 기계어로 한 줄씩 해석하는 총 시간보다 오래 걸릴 확률이 높고, 최적화가 되었기 때문에인터프리터가 실행 중에 기계어로 해석하는 시간을 제외하더라도실행시간은 인터프리트 방식보다 컴파일 방식이 더 빠를 확률이 높습니다. 이해를 돕기 위해, 계산을 쉽게 하기 위해 1초로 정한 점 양해 바랍니다.)
A 메소드가 딱 1번 호출된다면
컴파일 방식
인터프리트 방식
기계어로 번역 (1초)
기계어로 해석 (총 1초)
실행 (1초)
실행 (1초)
총 2초
총 2초
컴파일 방식이든 인터프리트 방식이든 총 시간은 2초로 똑같습니다.
A 메소드가 1000번 호출된다면
컴파일 방식
인터프리트 방식
기계어로 번역 (1초)
기계어로 해석 (총 1초)
실행 (1초)
실행 (1초)
실행 (1초)
기계어로 해석 (총1초)
실행 (1초)
실행 (1초)
실행 (1초)
기계어로 해석 (총1초)
실행 (1초)
실행 (1초)
실행 (1초)
기계어로 해석 (총1초)
실행 (1초)
실행 (1초)
실행 (1초)
기계어로 해석 (총1초)
실행 (1초)
실행 (1초)
실행 (1초)
기계어로 해석 (총1초)
. . .
. . .
총 1001초
총 2000초
실행 중에 인터프리트 방식으로 해석을 하면 해당 코드를 기계어로 해석하는 똑같은 작업을 1000번 하는 것입니다.
따라서 컴파일 방식은 1001초, 인터프리트 방식은 2000초가 걸릴 것입니다.
그리고 이 차이는 A 메소드가 많이 호출될수록 점점 커질 것입니다.
따라서 자주 실행되는 코드를 미리 기계어로 컴파일 해두면 실행시간을 훨씬 줄일 수 있을 것입니다.
그래서 JIT 컴파일러가 런타임에 동작하는 이유가 뭔데?
이러한 단점을 극복하기 위해서 Java 1.3 HotSpot VM부터 JIT 컴파일러를 도입하여 자주 실행되는 메소드는 실행 중에 기계어로 번역을 하는 방법을 채택합니다. 이 방법으로는 시작 시간은 여전히 빠르면서, 실행 중에 자주 실행되는 코드를 기계어로 번역을 하여 인터프리터 방식의 실행 속도가 느리다는 단점을 어느 정도 극복할 수 있습니다.
JIT 컴파일러가 런타임에 실행됨으로써 얻을 수 있는 장점은 이 뿐만이 아닙니다.
아래의 코드를 봅시다.
for (int i = 0; i < 1000; i++) {
// 코드 생략
}
위의 반복문을 보면 해당 반복문이 1000번 실행될 것이라는 것을 컴파일 시점에 알 수 있습니다.
int count = scanner.nextInt(); // 사용자의 입력을 받음
for (int i = 0; i < count; i++) {
// 코드 생략
}
하지만 이 코드는 반복문이 몇 번 실행될지 예측을 할 수 없습니다.
사용자의 입력값에 따라 반복문의 실행 횟수가 달라지기 때문입니다.
또한 서버 애플리케이션의 경우, 클라이언트가 어떤 API를 많이 호출하는지에 따라 특정 메소드의 실행 횟수가 달라지기 때문에 컴파일 시점에 더욱 더 예측을 하기가 어렵습니다.
하지만 런타임에는 이러한 정보들을 알 수 있습니다.
이렇게 런타임에 컴파일을 하게 되면동적 최적화를 할 수 있습니다. 컴파일 타임에는 알 수 없었던 정보들을 알 수 있기 때문에 프로그램의 실행 패턴 등 더 많은 정보를 기반으로 최적화를 할 수 있다는 장점이 있습니다.
따라서 자주 실행되는 코드를 미리 기계어로 컴파일 해두면 실행시간을 훨씬 줄일 수 있을 것입니다.
하지만 이 메소드가 자주 호출되는지 어떻게 아냐고!!
여기에서 JIT 컴파일러가 런타임에 수행됨으로써 얻을 수 있는 장점이 드러납니다.
그러면 특정 메소드가 어느 정도로 자주 호출되어야 JIT 컴파일러가 컴파일을 하게 되는 것일까요?
메소드가 몇 번 호출되어야 JIT 컴파일러가 컴파일을 할지 그 임계값은 -XX:CompileThreshold 옵션으로 지정할 수 있습니다.
만약 Test.class라는 클래스파일을 실행시킬 때, 메소드가 5000번 이상 호출되었을 때 JIT 컴파일을 하고 싶다면
java -XX:CompileThreshold=5000 Test
이렇게 해주면 됩니다.
Java 8 이상의 HotSpot JVM에서 CompileThreshold 옵션의 기본값은 10,000입니다.
따라서 아무런 설정을 해주지 않는다면 특정 메소드가 10,000번 호출되었을 때 JIT 컴파일러가 기계어로 번역을 해서 따로 캐싱해두는 것입니다.
위에서 말한 것처럼 JIT 컴파일러가 런타임에 동작하기 때문에 얻을 수 있는 장점이 많이 있습니다. 하지만 단점도 있습니다. JIT 컴파일을 한 후에는 성능이 빨라지겠지만 컴파일을 런타임에 하기 때문에 JIT 컴파일러가 컴파일을 하는 동안에는 응답시간이 지연될 수도 있습니다. 따라서 컴파일을 빠르게 하는 것도 중요합니다.
최적화를 잘 하면 컴파일 후의 코드는 성능이 매우 좋아지겠지만 컴파일 시간이 오래걸립니다.
최적화를 엄청 잘 하지는 않으면 컴파일 시간은 덜 걸려서 실행 중에 지연 시간은 덜 발생하겠지만 컴파일 후의 코드가 성능이 그렇게 좋아지지는 않을 것입니다.
지연 시간도 줄이고 최적화도 잘하면 매우 좋겠지만 하나를 개선하려면 하나를 포기해야 합니다.
JVM은 두 가지의 장점을 최대한 살릴 수 있도록 Tiered 컴파일이라는 방식을 채택합니다.
Tiered 컴파일러
Tiered 컴파일러는 한마디로 다단계 컴파일러라고 할 수 있습니다.
최적화가 아주 잘 된 코드를 '짱 좋은 코드', 그럭 저럭 최적화가 되어 컴파일된 코드를 '보통 코드'라고 하겠습니다.
(여기에서 '코드'는 기계어(machine code)를 말합니다)
특정 메소드가CompileThreshold 만큼 호출되어 JIT 컴파일러가 실행될 때 JIT 컴파일러는 바로 짱 좋은 코드로 컴파일하지 않습니다. 일단은 보통 코드로 컴파일합니다. 그러면 짱 좋은 코드로 컴파일 하는 것보다는 실행 중에 지연 시간이 덜 발생하겠죠?
그러다가 그 메소드가 더 많이 호출되어 일정 횟수를 초과하면 그 때 짱 좋은 코드로 다시 최적화를 하는 것입니다.
바이트코드에서 바로 짱 좋은 코드로 컴파일 하는 것보다 보통 코드에서 짱 좋은 코드로 최적화 하는 것이 시간이 훨씬 덜 소요됩니다.
이렇게 하면 지연시간을 최소화하면서 많이 호출되는 코드를 최적화가 아주 잘 된 코드로 컴파일 할 수 있는 것입니다.
Tiered 컴파일러에서 보통 코드로 컴파일하는 컴파일러를 C1, 짱 좋은 코드로 컴파일하는 컴파일러를 C2라고 합니다.
Java 9 이전에는 서버 컴파일러, 클라이언트 컴파일러라는 개념이 있었습니다.
Tiered 컴파일러로 따지면 보통 코드로 컴파일하는 C1 컴파일러가 클라이언트 컴파일러, 짱 좋은 코드로 컴파일하는 C2 컴파일러가 서버 컴파일러입니다.
실행을 할 때 서버 컴파일러 또는 클라이언트 컴파일러를 지정할 수 있었습니다.
하지만 Java 9부터 Tiered 컴파일러가 기본 옵션이 되었고 명시적으로 서버 컴파일러만을, 또는 클라이언트 컴파일러만을 사용할 수 없습니다.
(-XX:TieredCompilation 옵션으로 Tiered 컴파일러를 비활성화하여 C2 컴파일러(서버 컴파일러)만을 사용하도록 할 수는 있습니다.)
Code Cache
그러면 JIT 컴파일러가 이렇게 컴파일한 기계어를 어디에 저장할까요?
JVM 안의 Code Cache라는 곳에 저장됩니다.
Code Cache의 크기는 -XX:ReservedCodeCacheSize 옵션을 통해 지정할 수 있습니다.
Code Cache의 크기를 256MB로 설정하고 싶다면 -XX:ReservedCodeCacheSize=256m이라고 하면 됩니다.
만약에 코드 캐시 영역이 꽉 차면 더 이상 JIT 컴파일러가 동작하지 않습니다. 컴파일을 하더라도 컴파일된 기계어를 저장할 공간이 없기 때문입니다.
따라서 Code Cache 영역의 크기를 적절히 설정하는 것이 중요합니다.
그러면 GC가 돌 때 Stop-the-world가 발생하는 것처럼 JIT 컴파일러가 실행될 때 Stop-the-world가 발생하지 않을까요?
그렇지 않습니다. GC가 동작할 때는 살아있는 객체를 판별하기 위해서는 일단 애플리케이션의 실행을 멈춰야 합니다.
인구 조사를 예로 들어봅시다.
예를 들어 총 20층이고 각 층에는 10개의 가구가 있는 아파트가 있습니다.
인구 조사 담당자는 1층부터 20층까지 순차적으로 각 집을 돌면서 인구 조사를 합니다.
그런데 1층을 이미 조사하고 2층을 조사하고 있는 중에 1층에서 아기가 태어난다면 정확한 인구 조사를 못 하겠죠?
그렇기 때문에 GC가 돌 때는 애플리케이션의 실행을 멈추고 지금 살아있는 객체를 알아내는 것이고,
그래서 Stop-the-world가 발생하는 것입니다.
하지만 JIT 컴파일러는 상황이 다릅니다. 굳이 애플리케이션 실행을 중단할 필요가 없습니다.
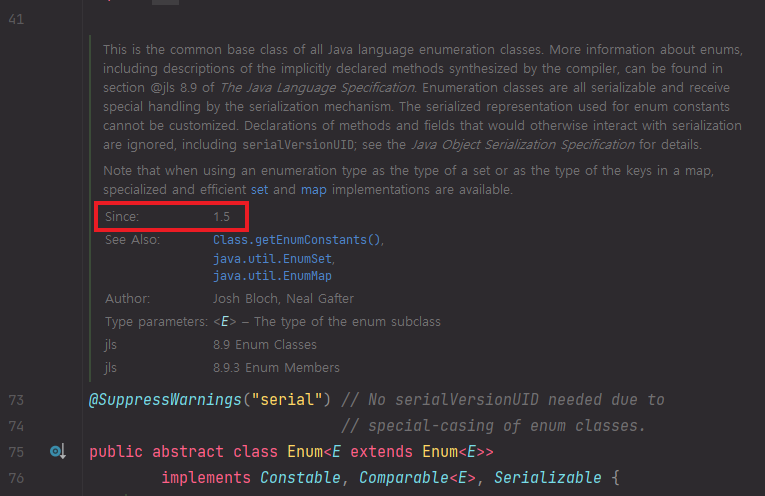
각각의 enum 상수의 인스턴스는 딱 1개이기 때문에 비교를 하려는 두 객체 중 적어도 하나가 enum 상수라면 equals() 대신 == 연산자로 비교해도 된다.
enum 상수는 인스턴스가 단 하나만 생성됩니다. (싱글톤)
따라서 어차피 같은 enum 상수라면 같은 인스턴스이기 때문에 굳이 equals() 메소드로 비교하지 않고 == 연산자를 통해서 비교를 하면 되는 것입니다.
clone() 메소드
CloneNotSupportedException을 던집니다. 이는 enum의 '싱글톤' 상태에 필수적인 '절대 복제되지 않음'을 보장합니다.
clone 메소드는 호출하면 무조건 예외가 발생합니다.
위의 equals() 메소드에서 설명했던 것처럼, enum은 인스턴스가 딱 1개인 싱글톤이기 때문에 객체를 복사할 수 없습니다.
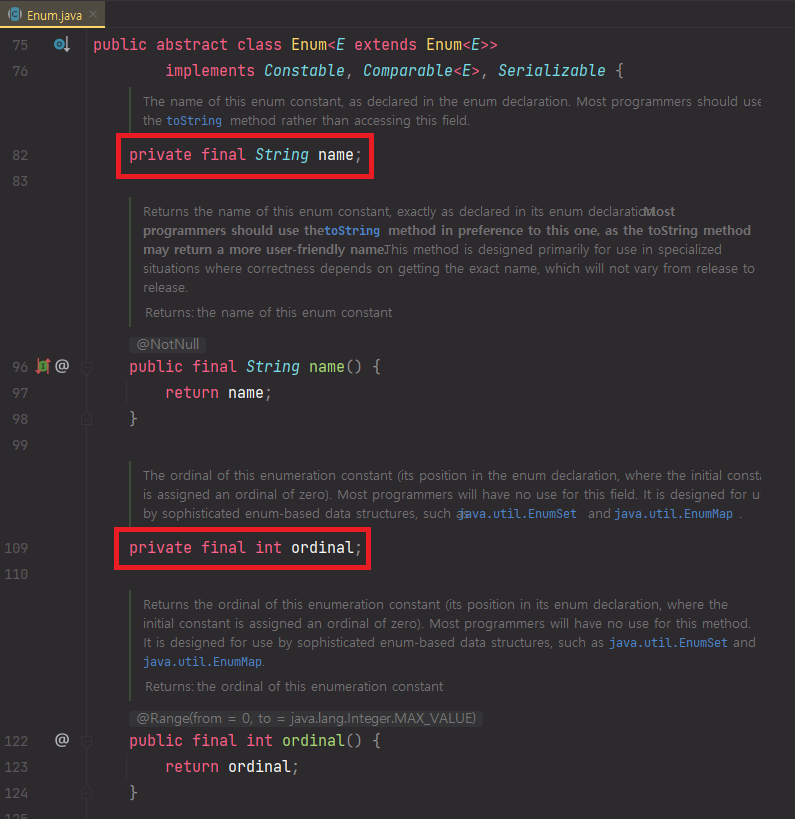
toString(), hashCode(), clone() 메소드
Object 클래스의 메소드인 equals(), toString(), hashCode(), clone() 메소드 중 toString()을 제외하고 모두 final로 선언되어있습니다.
toString()을 제외한 equals(), hashCode(), clone() 메소드는 저희가 재정의할 수 없습니다.
그리고 clone() 메소드는 아예 clone을 하지 못 하게 예외를 던지는 것을 볼 수 있습니다.
enum 상수들의 목록을 가져오려면 어떻게 해야 할까?
public enum Color {
RED, GREEN, BLUE;
}
만약 이 Color enum 타입의 상수들인 RED, GREEN, BLUE들을 배열로 가져오고 싶으면 어떻게 해야 할까요?
values() 라는 static 메소드를 사용하면 됩니다.
예를 들어 Color.values() 이렇게 말입니다.
public class EnumDemo {
public static void main(String[] args) {
Color[] colors = Color.values();
for (Color color : Color.values()) {
System.out.println(color);
}
}
}
위 코드를 실행하면
이렇게 Color enum 타입에 있는 상수들이 모두 출력되는 것을 볼 수 있습니다.
그런데 java.util.Enum 클래스에 들어가보면 values()라는 메소드는 없습니다.
그렇다면 도대체 values() 메소드는 어디에 정의되어 있는 것일까요?
자, 생각을 해봅시다.
자식은 부모를 알지만 부모는 자식을 모릅니다.
이것은 당연합니다.
java.lang.Enum 클래스를 상속받아서 만들어지는 enum 타입이 무엇일지 알지 못합니다.
Color라는 enum 타입을 만들 수도 있고 Grade라는 enum 타입을 만들 수도 있고, Category라는 enum 타입을 만들 수도 있고, Season이라는 enum 타입을 만들 수도 있고.... 가능한 enum 타입은 무한할 것입니다.
뿐만 아니라 Color 클래스의 enum 상수로 RED, YELLOW, GREEN이 올지, PINK, ORANGE, BLUE, PURPLE이 올지 등등 또한 무한할 것입니다.
따라서 java.lang.Enum 클래스는 자식을 모르기 때문에 values() 메소드를 구현할 수 없습니다.
오늘은 제가 개발을 하면서 겪은 문제와, 그 문제를 해결하기 위해 어떤 방법을 시도했고 어떻게 해결했는지 공유드리려고 합니다.
우선 문제 상황부터 공유드리겠습니다.
🤨 문제 상황
이 화면은 필터를 적용하여 상품을 조회하는 화면입니다.
이 화면에 따르면
상품 조회 API의 Request DTO에는
편의점
카테고리
행사 유형
최소 가격
최대 가격
Response DTO에는
상품 이미지
상품 이름
상품 가격
평점
리뷰 개수
해당 상품을 판매하는 편의점 + 해당 편의점의 행사 정보
현재 사용자의 좋아요 여부
현재 사용자의 북마크 여부
가 있어야 합니다.
여기에서 문제는 바로 빨간색으로 표시한 판매 편의점+행사 정보입니다.
response DTO 클래스는 아래와 같습니다.
public class ProductResponseDto {
private final Long productId; // 상품 상세 조회 화면으로 넘어가기 위해 필요
private final String productName;
private final Integer productPrice;
private final String productImageUrl;
private final String manufacturerName;
private final Boolean isLiked;
private final Boolean isBookmarked;
private final Integer reviewCount;
private final Double reviewRating;
private List<ConvenienceStoreEventDto> cvsEvents;
}
판매 편의점과 해당 편의점의 행사 정보를 담은 cvsEvents만 배열인 것을 볼 수 있습니다.
Java의 클래스에서는 하나의 객체에 List를 담을 수 있지만 데이터베이스에서는 그것이 불가능합니다. flat한 row들을 조회할 수 있을 뿐입니다. 이것이 바로 객체와 관계형 데이터베이스의 큰 차이점이자 저희를 머리 아프게 만드는 부분입니다.
또한 여기에서 하나의 리스트가 필요한 것처럼 보이지만 사실 두 개의 리스트가 필요한데요, 이해를 위해 먼저 ERD를 보여드리겠습니다.
아래는 ERD의 일부인데요,
각각의 테이블을 간단히 소개하자면
product: 상품
category: 카테고리
convenience_store: 편의점
manufacturer: 제조사
event: 행사 정보 (어떤 편의점에서 어떤 상품이 어떤 행사를 하는지)
sell_at: 어떤 상품이 어떤 편의점에 파는지
user: 사용자
review: 리뷰
product_like: 어떤 사용자가 어떤 상품에 좋아요 했는지
product_bookmark: 어떤 사용자가 어떤 상품에 북마크 했는지
입니다.
여기에서 event 리스트와 sell_at 리스트, 이렇게 두 개의 리스트가 필요한 것입니다.
화면에서 판매 편의점 정보와 해당 편의점의 행사 정보를 묶어서 보여주고 있기 때문에 sellAt 리스트와 event 리스트를 하나의 리스트로 합쳐서 response body에 넣어줄 뿐이고, 저희는 두 개의 리스트를 조회해야 합니다.
자 이제 문제 상황은 공유를 드렸으니 제가 어떤 방식으로 해결을 시도했는지 알아보겠습니다.
참고로 저는 필터 적용을 위해 동적 쿼리를 만들어야 해서 QueryDSL을 사용했습니다.
(사실 QueryDSL은 JPQL에 비해 훨씬 편리하고 컴파일 시점에 오류가 나서 실수도 줄일 수 있어서 꼭 동적쿼리가 아니라도 저는 QueryDSL을 잘 사용합니다. 한 번도 사용해보지 않으셨다면 꼭 한 번 사용해보세요! 아주 편리합니다👍)
첫번째 시도: Product 엔티티 안에 OneToMany로 List 두 개를 만들고 fetch join하여 Product 엔티티 자체를 조회하자
제가 처음으로 시도했던 방법은 Product 엔티티 안에 OneToMany로 List<Event> events, List<SellAt> sellAtList를 만들고 Product 엔티티를 sellAtList, events와 fetch join 하여 조회하는 방법이었습니다.
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class Product extends BaseTimeEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@NotNull
private String name;
private Integer price;
private String imageUrl;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "category_id")
private Category category;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "manufacturer_id")
private Manufacturer manufacturer;
@OneToMany(mappedBy = "product")
private List<Event> events = new ArrayList<>(); // 추가
@OneToMany(mappedBy = "product")
private List<SellAt> sellAtList = new ArrayList<>(); // 추가
}
이렇게 OneToMany로 가져오고 싶은 두 리스트를 Product 엔티티에 추가했습니다.
조회 결과가 N개일 때 N개에 대해 각각 1번씩 조회 쿼리를 날리는 것이 아니라 위와 같이 batch size만큼씩 한꺼번에 날리는 것입니다.
batch size를 정하지 않은 경우 조회 결과가 N개일 때 2 * N번 추가 쿼리가 나가서 총 1 + N * 2번 쿼리가 나갔겠지만
batch size를 정해준다면 조회 결과가 N개일 때 조회 결과의 개수와 상관없이 추가 쿼리가 딱 2번 나가서 총 1 + 2번의 쿼리가 나가게 됩니다. (batch size가 조회 결과의 개수보다 큰 경우에 한합니다. 조회 결과의 개수가 batch size보다 큰 경우 1 + ceil(N / batch size)번의 쿼리가 나갈 것입니다.)
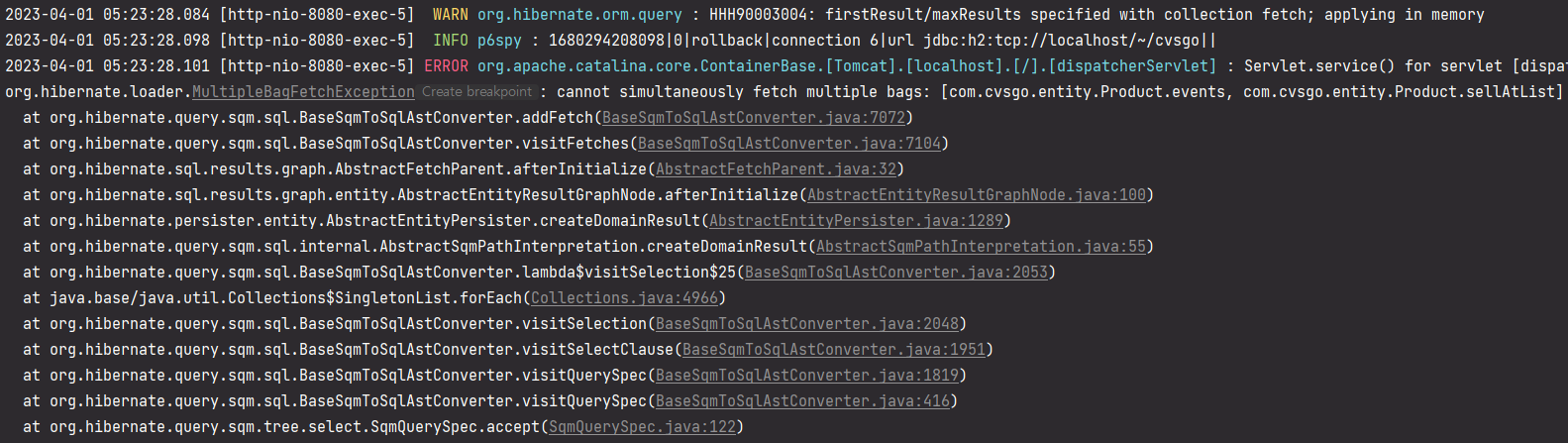
아까 to-many 관계는 fetch join을 2개 해줬더니MultipleBagFetchException이 났었죠?
위는 Hibernate 공식 문서인데요, to-one 관계는 fetch join을 여러 개 해도 완전히 안전하다고 나와있습니다.
따라서 to-one 관계인 category와 manufacturer는 fetch join으로 가져옵시다.
일단 저는 Java 17이 나온 이후로는 Java 버전을 17로 설정하여 프로젝트를 만들고 있습니다. (LTS 버전이기도 하고 Java 17의 stream 메소드 toList()가 너무 편리하더라고요?ㅎㅎ collect(Collectors.toList()) 안 쓰고 저거 쓰니까 아주 신세계...👍)
그런데 매번 오류가 났습니다. 왜냐하면 제 컴퓨터에는 JDK 11이 기본으로 설정되어 있거든요.. (환경변수 설정만 바꿔주면 되는데 말이죠...... 그게 귀찮아서.........)
그래서 저는 당연히
'프로젝트를 생성할 때 Java 버전을 17로 만들었는데 내 컴퓨터의 default JDK 버전이 11이니까 당연히 JDK 17이 없다고 오류가 나겠지'
하면서 항상 인텔리제이의 Settings에 들어가서 JDK 17로 바꿔주고 실행을 했었습니다.
그런데 얼마 전 블로그를 작성하다가, 예제 코드를 깃허브에 올려두려고 프로젝트를 다시 만들었습니다.
제 블로그를 읽으시는 분들이 JDK 17이 설치가 안 되어 있을 수도 있으니 Java 11로 만들어야겠다! 하고 Spring Boot 3.0.4, Java 11로 프로젝트를 만들었습니다.
그런데 여전히 똑같은 오류가 나는 것입니다!!!
아니 Java 11로 프로젝트를 만들었고 내 컴퓨터에 설치된 JDK도 11 버전인데 왜 오류가 나는거지??
검색을 해보니 Spring Boot 3.0부터는 Java 17 이상만 지원한다고 합니다.
이 사실을 몰랐을 때부터 매번 무심코 해줬던 설정인데,
Spring Boot 3.0 이상부터는 Java 17부터만 된다는 사실을 알게 된 기념(?)으로
같은 문제로 어려움을 겪고 계신 분들께 조금이나마 도움이 되기를 바라며 제가 해결한 방법을 공유하고자 합니다.
✅ 실행 환경
일단 저의 환경을 공유해드리자면 시스템의 환경변수로 등록되어 있는 것은 JDK 11입니다.
하지만 제 컴퓨터에는 JDK 8, JDK 11, JDK 17이 설치되어 있습니다.
스프링 부트 버전은 3.0.4입니다.
✅ 문제
스프링 부트 3.0 이상의 프로젝트를 열었더니 이런 오류가 발생합니다.
A problem occurred configuring root project '프로젝트명'.
> Could not resolve all files for configuration ':classpath'.
> Could not resolve org.springframework.boot:spring-boot-gradle-plugin:3.0.4.
Required by:
project : > org.springframework.boot:org.springframework.boot.gradle.plugin:3.0.4
> No matching variant of org.springframework.boot:spring-boot-gradle-plugin:3.0.4 was found. The consumer was configured to find a runtime of a library compatible with Java 11, packaged as a jar, and its dependencies declared externally, as well as attribute 'org.gradle.plugin.api-version' with value '7.6.1' but:
- Variant 'apiElements' capability org.springframework.boot:spring-boot-gradle-plugin:3.0.4 declares a library, packaged as a jar, and its dependencies declared externally:
- Incompatible because this component declares an API of a component compatible with Java 17 and the consumer needed a runtime of a component compatible with Java 11
- Other compatible attribute:
- Doesn't say anything about org.gradle.plugin.api-version (required '7.6.1')
- Variant 'javadocElements' capability org.springframework.boot:spring-boot-gradle-plugin:3.0.4 declares a runtime of a component, and its dependencies declared externally:
- Incompatible because this component declares documentation and the consumer needed a library
- Other compatible attributes:
- Doesn't say anything about its target Java version (required compatibility with Java 11)
- Doesn't say anything about its elements (required them packaged as a jar)
- Doesn't say anything about org.gradle.plugin.api-version (required '7.6.1')
- Variant 'mavenOptionalApiElements' capability org.springframework.boot:spring-boot-gradle-plugin-maven-optional:3.0.4 declares a library, packaged as a jar, and its dependencies declared externally:
- Incompatible because this component declares an API of a component compatible with Java 17 and the consumer needed a runtime of a component compatible with Java 11
- Other compatible attribute:
- Doesn't say anything about org.gradle.plugin.api-version (required '7.6.1')
- Variant 'mavenOptionalRuntimeElements' capability org.springframework.boot:spring-boot-gradle-plugin-maven-optional:3.0.4 declares a runtime of a library, packaged as a jar, and its dependencies declared externally:
- Incompatible because this component declares a component compatible with Java 17 and the consumer needed a component compatible with Java 11
- Other compatible attribute:
- Doesn't say anything about org.gradle.plugin.api-version (required '7.6.1')
- Variant 'runtimeElements' capability org.springframework.boot:spring-boot-gradle-plugin:3.0.4 declares a runtime of a library, packaged as a jar, and its dependencies declared externally:
- Incompatible because this component declares a component compatible with Java 17 and the consumer needed a component compatible with Java 11
- Other compatible attribute:
- Doesn't say anything about org.gradle.plugin.api-version (required '7.6.1')
- Variant 'sourcesElements' capability org.springframework.boot:spring-boot-gradle-plugin:3.0.4 declares a runtime of a component, and its dependencies declared externally:
- Incompatible because this component declares documentation and the consumer needed a library
- Other compatible attributes:
- Doesn't say anything about its target Java version (required compatibility with Java 11)
- Doesn't say anything about its elements (required them packaged as a jar)
- Doesn't say anything about org.gradle.plugin.api-version (required '7.6.1')
* Try:
> Run with --info or --debug option to get more log output.
> Run with --scan to get full insights.
안녕하세요 오늘은 Spring에서 제공하는 정말 편리한 기능인 HandlerMethodArgumentResolver에 대해 알아보겠습니다. HandlerMethodArgumentResolver는 무엇이고 어떤 경우에 사용하는 것이 좋을까요? 예제를 보며 함께 알아보는 시간을 가져봅시다.
❓ 대부분의 API에 필요한 공통적인 로직이 있다면 어떻게 처리하는 것이 좋을까?
공통적인 로직이 있다면 스프링에서는 interceptor, filter, AOP 등 다양한 방법으로 처리할 수 있습니다. 하지만 공통적인 로직을 처리하여 어떤 결과값을 컨트롤러에 넘겨줘야 한다면 어떻게 하는 것이 좋을까요?
예를 들어, 클라이언트 측에서 header에 토큰을 담아서 request를 보내는 경우가 있다고 가정해봅시다. 그리고 아래와 같이 거의 모든 API에서 해당 요청을 보낸 사용자가 누구인지 사용자 정보가 필요합니다.
package com.feelcoding.argumentresolverdemo.controller;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestHeader;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequiredArgsConstructor
@Slf4j
public class TestController {
@GetMapping("/test1")
public void test1(@RequestHeader String token) {
// 이 API에서는 사용자 정보가 필요합니다!
}
@PostMapping("/test2")
public void test2(@RequestHeader String token) {
// 이 API에서도 사용자 정보가 필요합니다!
}
@GetMapping("/test3")
public void test3(@RequestHeader String token) {
// 이 API에서도 사용자 정보가 필요합니다!
}
@GetMapping("/test4")
public void test4(@RequestHeader String token) {
// 이 API에서도 사용자 정보가 필요합니다!
}
}
이 경우, 사용자의 정보를 알아내는 코드가 여러 곳에서 중복될테니 토큰으로부터 사용자 정보를 알아내 User 객체를 리턴해주는 메소드를 따로 뽑는 것이 나을 것 같습니다.
🤨 중복되는 로직을 메소드로 만들어보자
public User getLoginUser(String token) {
return userRepository.findByEmail(token).orElseThrow();
}
토큰으로부터 사용자 정보를 알아내서 User 객체를 리턴하는 메소드를 이렇게 만들었습니다! (원래는 토큰을 파싱해서 사용자 정보를 알아내야 하는데 여기에서 토큰에 대한 설명까지 하면 토큰에 대한 글이 될 것 같아 토큰 부분에 이메일을 헤더에 담아 보내는 것으로 했습니다😅)
package com.feelcoding.argumentresolverdemo.controller;
import com.feelcoding.argumentresolverdemo.User;
import com.feelcoding.argumentresolverdemo.dto.SignUpRequestDto;
import com.feelcoding.argumentresolverdemo.dto.SignUpResponseDto;
import com.feelcoding.argumentresolverdemo.service.AuthService;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestHeader;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequiredArgsConstructor
@Slf4j
public class TestController {
private final AuthService authService;
@GetMapping("/test1")
public void test1(@RequestHeader String token) {
User user = authService.getLoginUser(token);
// 어쩌구 저쩌구
}
@PostMapping("/test2")
public void test2(@RequestHeader String token) {
User user = authService.getLoginUser(token);
// 어쩌구 저쩌구
}
@GetMapping("/test3")
public void test3(@RequestHeader String token) {
User user = authService.getLoginUser(token);
// 어쩌구 저쩌구
}
@GetMapping("/test4")
public void test4(@RequestHeader String token) {
User user = authService.getLoginUser(token);
// 어쩌구 저쩌구
}
}
메소드로 따로 뺐기 때문에 그냥 중복되는 코드를 여러 번 작성하는 것보다는 낫겠지만, 사용자 정보가 필요한 컨트롤러마다 이렇게 코드가 반복되어 들어갔습니다.
🤔 @LoginUser 어노테이션만 달면 컨트롤러 메소드에 User 객체를 넣어주면 얼마나 좋을까?
헤더에 있는 토큰을 읽어서 User 객체를 반환해주는 이런 공통적인 부분을 어딘가에서 처리해서 컨트롤러의 매개변수로 User 객체를 짠! 하고 넘겨주면 얼마나 좋을까요? 이렇게 말입니다.
@GetMapping("/test1")
public void test1(@LoginUser User user) {
// 어쩌구 저쩌구
}
@PostMapping("/test2")
public void test2(@LoginUser User user) {
// 어쩌구 저쩌구
}
@GetMapping("/test3")
public void test3(@LoginUser User user) {
// 어쩌구 저쩌구
}
@GetMapping("/test4")
public void test4(@LoginUser User user) {
// 어쩌구 저쩌구
}
HandlerMethodArgumentResolver를 사용하면 이것이 가능해집니다!
❗ HandlerMethodArgumentResolver를 사용하여 사용자 정보를 쉽게 받아오자
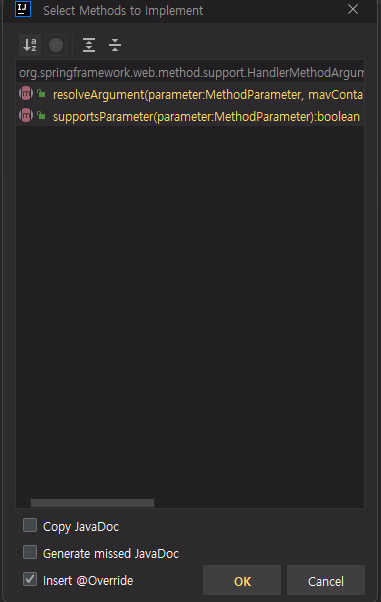
위와 같이 @LoginUser와 같은 어노테이션 하나로 컨트롤러에서 쉽게 User 객체를 얻어오려면 세 가지를 해야 합니다.
@LoginUser 어노테이션을 만들어줍니다.
HandlerMethodArgumentResolver를 구현한 클래스를 만들어야 하고
이렇게 구현한 HandlerMethodArgumentResolver를 등록해주어야 합니다.
하나씩 해볼까요?
1️⃣ LoginUser 어노테이션을 만들어줍니다.
LoginUser라는 어노테이션 이름은 제가 임의로 정한 것이고 원하는대로 변경하셔서 사용하시면 됩니다.
어노테이션을 만들 때는 interface 앞에 @를 붙이면 됩니다. @Target(ElementType.PARAMETER)은 해당 어노테이션이 매개변수에 쓰일 것이기 때문에 PARAMETER로 해주었습니다. @Retention(RetentionPolicy.RUNTIME)은 해당 어노테이션이 런타임까지도 쓰일 것이기 때문에 RUNTIME으로 해주었습니다.
LoginUserArgumentResolver를 @Component를 이용하여 빈으로 등록해준 이유는 뒤에서 설명하겠습니다.
3️⃣ 구현한 HandlerMethodArgumentResolver를 등록해줍니다.
이제 저희가 만든 LoginUserArgumentResolver를 등록해봅시다. HandlerMethodArgumentResolver 등록을 위해서는 WebMvcConfigurer를 구현한 클래스가 필요합니다. (저는 WebConfig라는 이름으로 클래스를 만들었습니다.) 그리고 addArgumentResolvers()라는 메소드를 구현해야 합니다. 이 메소드에서 아까 저희가 만든 LoginUserArgumentResolver를 추가해주시면 됩니다.
package com.feelcoding.argumentresolverdemo.config;
import com.feelcoding.argumentresolverdemo.util.LoginUserArgumentResolver;
import lombok.RequiredArgsConstructor;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.method.support.HandlerMethodArgumentResolver;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
import java.util.List;
@Configuration
@RequiredArgsConstructor
public class WebConfig implements WebMvcConfigurer {
private final LoginUserArgumentResolver loginUserArgumentResolver;
@Override
public void addArgumentResolvers(List<HandlerMethodArgumentResolver> resolvers) {
resolvers.add(loginUserArgumentResolver);
}
}
이렇게 해주시면 됩니다. 아까 LoginUserArgumentResolver를 빈으로 등록한 이유가 바로 여기에서 주입받아 사용하기 위함이었습니다.
드디어 완성이 되었습니다. 이제 컨트롤러에서 User 객체를 받아볼까요?
🔥컨트롤러에서 현재 로그인한 사용자의 User 객체를 매개변수로 받아보자
컨트롤러의 매개변수로 User 정보를 잘 받아오는지 확인해봅시다.
우선 매개변수에 @LoginUser 어노테이션과 User 매개변수를 추가해줍니다. 그리고 사용자 정보를 잘 가져오는지 확인하기 위해 로그를 남겨봅시다.
package com.feelcoding.argumentresolverdemo.controller;
import com.feelcoding.argumentresolverdemo.User;
import com.feelcoding.argumentresolverdemo.util.LoginUser;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequiredArgsConstructor
@Slf4j
public class TestController {
@GetMapping("/test1")
public void test1(@LoginUser User user) {
log.debug("여기는 test1, 사용자의 이름은 {}, 이메일은 {}", user.getName(), user.getEmail());
}
@PostMapping("/test2")
public void test2(@LoginUser User user) {
log.debug("여기는 test2, 사용자의 이름은 {}, 이메일은 {}", user.getName(), user.getEmail());
}
@GetMapping("/test3")
public void test3(@LoginUser User user) {
log.debug("여기는 test3, 사용자의 이름은 {}, 이메일은 {}", user.getName(), user.getEmail());
}
@GetMapping("/test4")
public void test4(@LoginUser User user) {
log.debug("여기는 test4, 사용자의 이름은 {}, 이메일은 {}", user.getName(), user.getEmail());
}
}
이제 Postman을 통해 API들을 호출해봅시다.
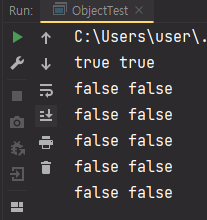
이렇게 헤더에는 Authorization이라는 이름으로 사용자의 이메일을 넣어주고 GET /test1, POST /test2, GET /test3, GET /test4 API들을 차례로 호출해보겠습니다.
이렇게 사용자 정보를 모두 다 잘 가져온 것을 볼 수 있습니다.
이렇게 HandlerMethodArgumentResolver를 사용하면 여러 곳에서 사용되는 공통적인 로직을 줄이고, 매개변수로 필요한 정보를 손쉽게 가져올 수 있습니다. 예시를 로그인으로 들었지만, 필요할 때 여러 방법으로 활용하시면 될 것 같습니다.
public class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
}
이름과 나이를 상태로 가지는 Person이라는 클래스를 만들었습니다.
public class EqualsTest {
public static void main(String[] args) {
Person p1 = new Person("김땡땡", 20);
Person p2 = new Person("김땡땡", 20);
Person p3 = p2;
Person p4 = new Person("이땡땡", 25);
System.out.println(p1.equals(p2));
System.out.println(p1.equals(p3));
System.out.println(p1.equals(p4));
System.out.println(p2.equals(p3));
System.out.println(p2.equals(p4));
System.out.println(p3.equals(p4));
}
}
p1과 p2는 이름과 나이가 모두 같고, p2와 p3는 같은 객체입니다.
p4는 p1, p2, p3과 다른 객체이고 내용도 다릅니다.
그리고 이 코드를 실행하면 어떤 결과가 나올까요?
.
.
.
.
.
.
.
.
.
.
.
.
.
.
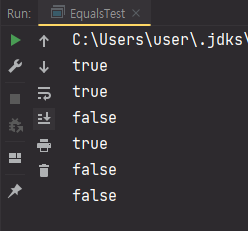
결과는 이렇습니다.
같은 객체인 p2와 p3의 비교에서만 true를 리턴했습니다.
p1과 p2는 나이와 이름이 모두 같은데 왜 equals()로 비교를 했을 때 다르다고 나왔을까요?
사실 이는 당연한 결과입니다. Object 클래스의 equals()는 ==으로 비교한 것과 똑같은 것을 확인했었죠?
제가 만든 Person 클래스는 Object 클래스를 상속받기 때문에 Object의 equals()와 동일합니다.
따라서 Person 객체들을 ==으로 비교한 것과 결과가 똑같이 같은 객체인 경우에만 true를 반환했던 것입니다.
그런데 저는 같은 객체일 때가 아니라 이름과 나이가 모두 동일할 때 true를 반환하고 싶습니다.
그러면 어떻게 해야 할까요?
이름과 나이가 같으면 true를 반환하도록 equals() 메소드를 오버라이딩(재정의) 해주면 됩니다.
@Override
public boolean equals(Object o) {
if (o instanceof Person) {
Person p = (Person) o;
if (p.getName() != null && p.getName().equals(this.name) && p.getAge() == this.age) {
return true;
} else {
return false;
}
} else {
return false;
}
}
저는 이렇게 작성해보았습니다.
equals() 메소드를 오버라이딩 했으니 이제 아까 코드를 다시 실행해볼까요?
public class EqualsTest {
public static void main(String[] args) {
Person p1 = new Person("김땡땡", 20);
Person p2 = new Person("김땡땡", 20);
Person p3 = p2;
Person p4 = new Person("이땡땡", 25);
System.out.println(p1.equals(p2));
System.out.println(p1.equals(p3));
System.out.println(p1.equals(p4));
System.out.println(p2.equals(p3));
System.out.println(p2.equals(p4));
System.out.println(p3.equals(p4));
}
}
이제 실행결과가 어떻게 나올까요?
이렇게 이름과 나이가 같은 p1과 p2의 비교에서 true를 리턴한 것을 볼 수 있습니다.
또한 p3는 p2와 동일한 객체이기 때문에 p1과 p3의 비교에서도 true가 나왔습니다.
그런데 equals() 메소드를 오버라이딩할 때 주의할 점이 있습니다.
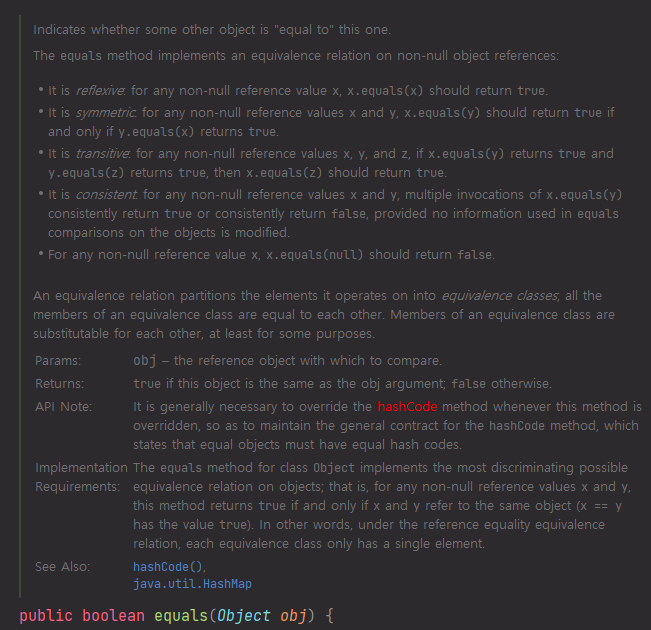
이것은 Object 클래스의 equals() 메소드에 달린 주석입니다.
다른 객체가 이것과 같은지 아닌지를 나타냅니다. equals() 메소드는 null이 아닌 참조 객체에 대해 비교를 수행합니다. 재귀적이다. null이 아닌 참조 타입 객체 x가 있을 때 x.equals(x)는 true를 반환해야 한다. 대칭적이다. null이 아닌 참조 타입 객체 x. y가 있을 때 y.equals(x)가 true일 때만 x.equals(y)가 true여야 한다. 전이적이다. null이 아닌 참조 타입 객체 x, y, z가 있을 때, x.equals(y)가 true이고 y.equals(z)가 true이면 x.equals(z)는 true를 반환해야 한다. 일관적이다. null이 아닌 참조 타입 객체 x, y가 있을 때 x.equals(y)를 여러 번 호출해도 일관적으로 계속 true를 반환하거나 일관적으로 계속 false를 반환해야 한다. null이 아닌 참조 타입 객체 x가 있을 때, x.equals(null)은 false를 리턴해야 한다.
(의역이 있을 수 있습니다.)
equals() 메소드를 오버라이딩 할 때는 위 규칙들을 반드시 지키며 재정의해야 합니다.
또한 equals() 메소드를 오버라이딩할 땐 hashCode() 메소드도 오버라이딩하는 것이 좋습니다.
그렇지 않으면 HashSet이나 HashMap을 사용할 때 원치 않는 결과를 얻을 수 있습니다.
무슨 말인지 아직 와 닿지 않으시죠? 한 번 예를 들어보겠습니다.
아까 제가 구현한 Person 클래스를 key로 가지는 HashMap을 만들어보겠습니다.
import java.util.HashMap;
import java.util.Map;
public class HashMapTest {
public static void main(String[] args) {
Map<Person, Integer> map = new HashMap<>();
Person p1 = new Person("김땡땡", 20);
Person p2 = new Person("김땡땡", 20);
map.put(p1, 1);
map.put(p2, 2);
System.out.println(map.size());
}
}
아까 저희는 이름과 나이가 같으면 true를 리턴하도록 equals() 메소드를 재정의했습니다.
이름과 나이가 같은 객체 p1과 p2를 만들고 map에 한 번은 p1을 key로, 한 번은 p2를 key로 엔트리를 추가했습니다.
이 코드의 결과는 어떻게 될까요?
1을 출력할까요? 2를 출력할까요?
.
.
.
.
.
.
.
.
.
.
.
.
.
.
2를 출력합니다.
이상하지 않나요?
key 값이 같으니 덮어써질 것 같은데, 왜 다른 key로 인식하는 것일까요?
그 이유는 hashCode()를 재정의하지 않았기 때문입니다.
Object 클래스의 equals() 메소드에 달린 주석
같은 객체는 같은 해시코드를 가져야 한다는 hashCode() 메소드의 일반적인 규칙을 유지하기 위해서 equals() 메소드를 오버라이딩 했을 때는 일반적으로 hashCode()를 반드시 오버라이딩해야 한다.
위에 써있는 것처럼 equals() 메소드를 오버라이딩 했다면 equals() 메소드 비교에서 true를 반환하는 두 객체는 hashCode() 메소드에서도 같은 해시코드를 반환해야 합니다.
HashMap은 equals() 메소드와 hashCode() 메소드 모두 같아야 동일한 key로 인식합니다.
따라서 위 코드의 실행 결과 1을 출력하기를 원한다면 hashCode()를 오버라이딩하여 hashCode()의 리턴값까지 같게 만들어줘야 합니다.
한 번 hashCode() 메소드를 오버라이딩해보겠습니다.
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
이렇게 hashCode() 메소드까지 오버라이딩 했으니 다시 아까 코드를 실행해볼까요?
import java.util.HashMap;
import java.util.Map;
public class HashMapTest {
public static void main(String[] args) {
Map<Person, Integer> map = new HashMap<>();
Person p1 = new Person("김땡땡", 20);
Person p2 = new Person("김땡땡", 20);
map.put(p1, 1);
map.put(p2, 2);
System.out.println(map.size());
}
}
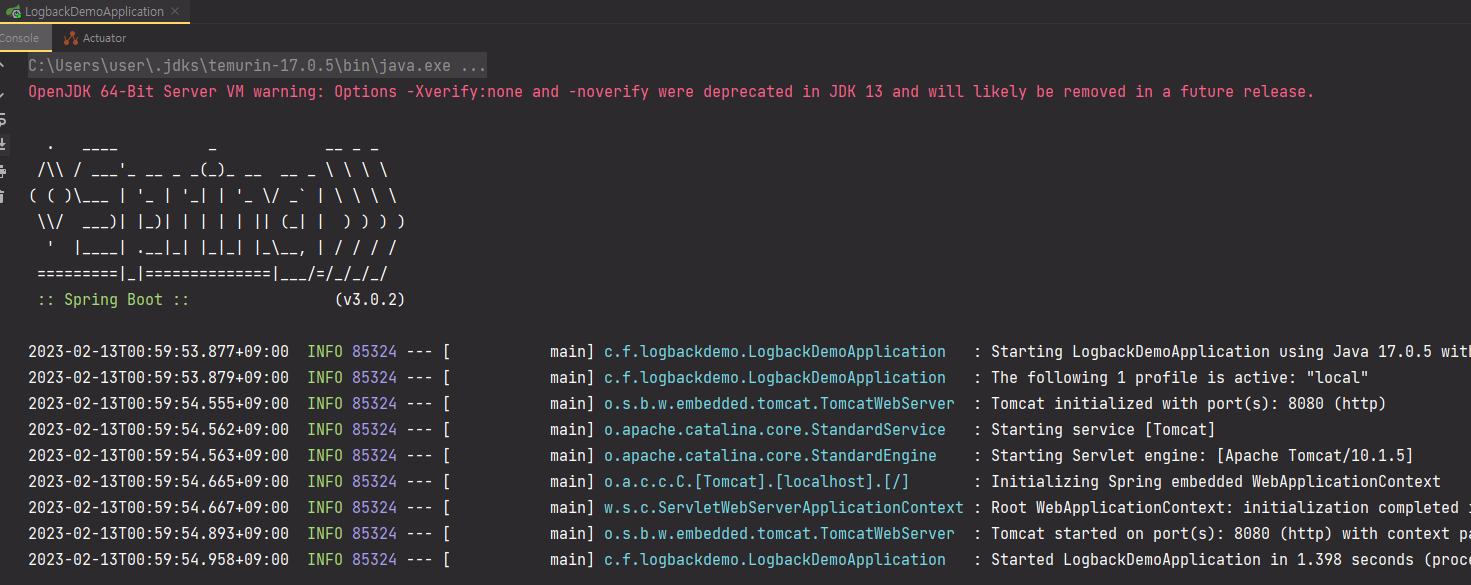
그런데 INFO, WARN, ERROR 등 로그 레벨을 나타내는 글자 색은 아까 아무런 설정을 해주지 않았을 때의 색이 더 예쁜 것 같은데... 바꿀 수 없을까요?
아무 설정을 해주지 않았을 때의 로그 색상
그럼 기본 설정이 어떻게 되어 있는지, 기본 설정이 되어 있는 곳을 찾아가봅시다.
Windows 사용자는 ctrl + n, Mac OS 사용자는 cmd + o를 누르고 우측 상단에 범위를 Files 탭에서 base.xml을 검색해봅시다. (base.xml이라고 입력하면 자동으로 범위가 All Places로 바뀔 것인데, 만약 나오지 않는다면 우측 상단의 범위를 All Places로 수정해보세요.)
해당 파일에 들어가보면
defaults.xml 파일을 include 했다는 것을 알 수 있습니다.
그러면 다시 검색을 해서 defaults.xml 파일에 가봅시다.
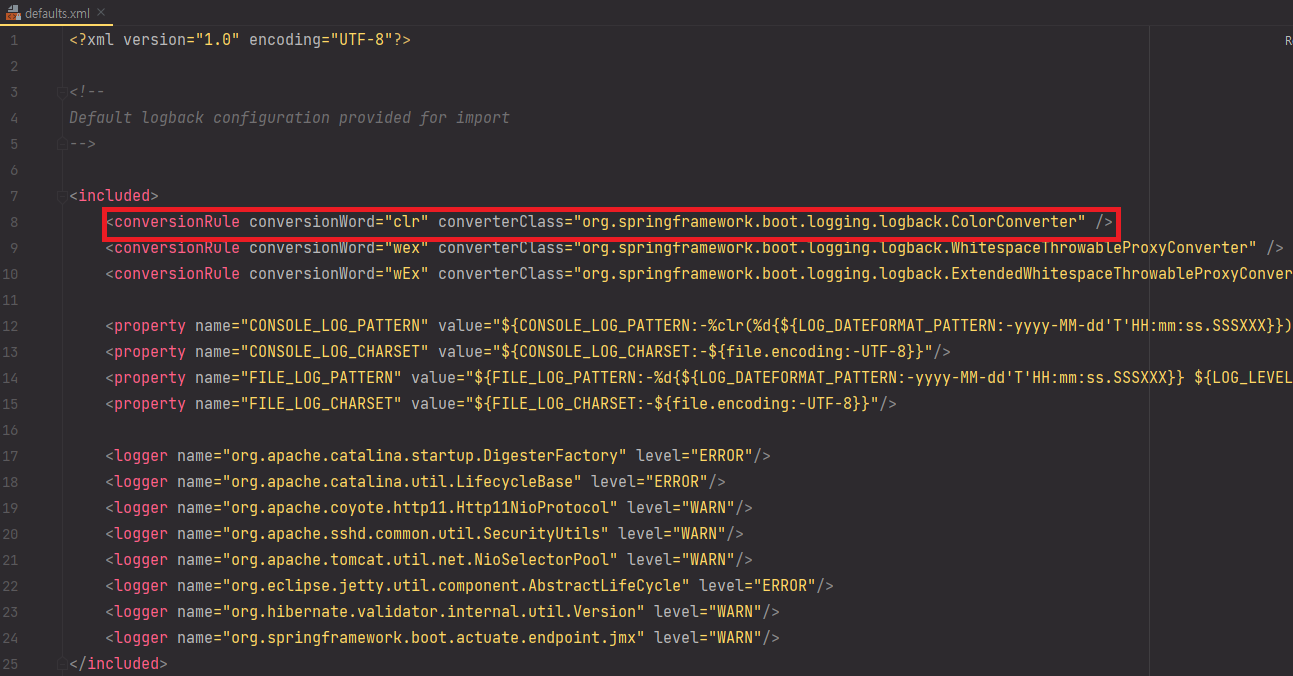
defaults.xml을 보면
여기에 clr이라는 이름으로 conversionRule이 선언되어 있고
defaults.xml
로그 레벨을 지정하는 부분을 clr이라는 색으로 지정한 것을 볼 수 있습니다.
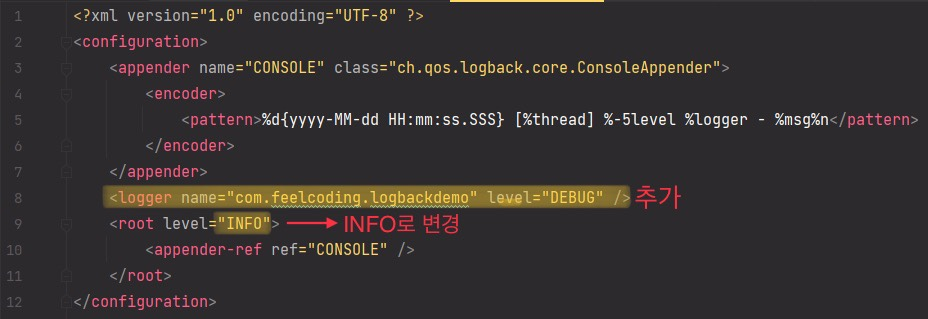
저는 로그 레벨을 해당 색으로 변경하고 logger만 cyan 색으로 하고 나머지는 그냥 기본 색으로 바꾸겠습니다.
예를 들어 2023-02-13.0.log 파일에 로그가 많이 써져서 100MB가 넘으면 2023-02-13.1.log 파일에 기록을 하고, 그 다음 2023-02-13.2.log, 2023-02-13.3.log, ... 이런 식으로 파일 이름을 짓겠다는 것입니다. 그리고 30일 후인 2023년 3월 15일에 이 파일은 삭제될 것입니다.